

Historique du jeu
Ce jeu a été créé il y a 2 ans (fin juillet 2016) :
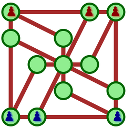
À la rentrée suivante, il a été intégré à l’atelier « jeux mathématiques » de l’IREM et imprimé pour les animations de l’IREM :
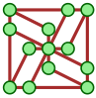
Ce jeu a donc été exploré, par des joueurs humains (parfois très jeunes, voire plus jeunes que la créatrice du jeu), à ces occasions :
- fête de la science 2016
- semaine des maths 2017
- fête de la science 2017
- semaine des maths 2018
- fête de la science 2018
Ces explorations n’ont pas permis de dégager une éventuelle stratégie gagnante ni pour les bleus ni pour les rouges. Il semblerait même que lorsque les deux joueurs jouent défensif, on aboutisse à une partie nulle. Par contre la victoire par blocage de l’adversaire, même si elle est rare, peut survenir et pourrait être la clé d’une stratégie gagnante.
Des généralisations du jeu sont jouables à la partie « jeu des parkings » de ce site. Elles n’éclairent pas vraiment sur la question puisque dans la version 1×1, les bleus n’ont d’autre choix que bloquer les rouges, il en est de même pour la version 1×2, mais par contre la version 2×1 semble comporter une stratégie gagnante pour les rouges ...
Démarche bayésienne
Une première idée est de faire jouer la machine contre elle-même, au hasard, et regarder quels sont les premiers coups ayant donné la victoire aux rouges, mais aussi si la victoire par blocage apparaît souvent comparée à la victoire par rapidité dans la course. Pour cela on va simuler le jeu au hasard en Python. Et pour cela, il faut d’abord trouver comment on représente le graphe en Python. Par l’expérience de codingame, c’est sous forme de liste de listes (de sommets voisins) que le graphe sera représenté. Avec la numérotation [1] visible dans le chapeau de cet article, le graphe est décrit ainsi :
graphe = [[1,3,5],[2,6],[4,7],[6],[6],[6,10],[7,8,9,11],[12],[10],[12],[11],[12],[]]
def voisins(a,b):
return a in graphe[b] or b in graphe[a]Pour économiser, on n’a représenté chaque arête qu’une fois, et la fonction voisins(a,b) tient compte de la symétrie dûe au fait que le graphe est non orienté : Pour que a et b soient voisins, il faut que, ou bien a soit dans graphe[b], ou bien que b soit dans graphe[a]. On remarque que la fonction voisins est booléenne. Ce genre de fonctions facilite la rédaction d’un programme Python qui soit proche de la langue naturelle.
On utilisera 2 autres variables globales : bleus qui est la liste des sommets où se trouvent actuellement les trois voitures bleues, et rouges qui est la liste des positions des voitures rouges :
bleus = [0,1,2]
rouges = [10,11,12]
def vide(sommet):
return sommet not in bleus and sommet not in rougesDire qu’un sommet du graphe est vide, c’est dire qu’il ne figure ni dans la liste des positions des voitures bleues, ni dans celle des voitures rouges. Là encore, il s’agit d’une fonction booléenne, qu’il aurait peut-être été plus judicieux de nommer est_vide que vide. Les fonctions booléennes suivantes disent si les bleus (respectivement, les rouges) peuvent mener une voiture de a vers b : Cela signifie qu’il y a une voiture en a, que le sommet b est vide (sinon on ne peut pas y ajouter la voiture qui est en a) et que les sommets sont adjacents :
def bleupeut(a,b):
return a in bleus and voisins(a,b) and vide(b)
def rougepeut(a,b):
return a in rouges and voisins(a,b) and vide(b)Les fonctions précédentes permettent de définir de manière proche du langage naturel, la liste des coups possibles pour les bleus : C’est la liste des couples de sommets a et b tels que bleupeut(a,b) :
def choixbleus():
return [(a,b) for a in bleus for b in range(13) if bleupeut(a,b)]
def choixrouges():
return [(a,b) for a in rouges for b in range(13) if rougepeut(a,b)]Avec ces fonctions, on peut programmer la manière dont les bleus jouent au hasard (le module random a été importé au début du script) : Ils choisissent au hasard (avec choice du module random) un couple (début,fin) de sommets qu’ils peuvent jouer (autrement dit, un coup jouable au hasard) ; puis
- ils enlèvent (« remove ») la voiture du sommet début puisqu’elle démarre son périple vers la fin du coup ;
- ils placent (« append ») la voiture sur le sommet fin
- ils trient (« sort ») dans l’ordre croissant la liste bleus
def bleusjouent():
if not rougesgagnent():
debut,fin = choice(choixbleus())
bleus.remove(debut)
bleus.append(fin)
bleus.sort()Mais tout ceci, ils ne doivent pas le faire si les rouges ont gagné. Pour savoir si les rouges ont gagné, on regarde si leurs trois voitures sont arrivées ou s’il n’y a aucun choix possible pour les bleus :
def bleusgagnent():
return bleus==[10,11,12] or len(choixrouges())==0
def rougesgagnent():
return rouges==[0,1,2] or len(choixbleus())==0
def fini():
return bleusgagnent() or rougesgagnent()On en a profité pour définir un test de fin du jeu : Le jeu est fini lorsque l’un des joueurs a gagné. À ce stade, rien ne prouve que la durée de vie du jeu est finie, il peut très bien y avoir des situations de jeu qui se répètent à l’infini, et dans ce cas il faudra annoncer la partie comme nulle (il n’est donc pas certain qu’il y ait une stratégie gagnante, puisqu’il peut y avoir une sorte de ko (go)). Pour simuler une partie il suffit maintenant de faire ceci :
while not fini():
rougesjouent()
bleusjouent()Voici la présentation faite lors des 20 ans de l’IREM, où on voit notamment les utilisations des fonctions par d’autres fonctions :
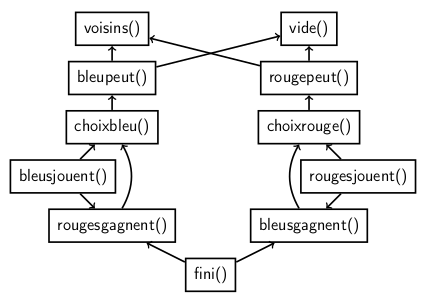
Voici comment on peut jouer aléatoirement à ce jeu :

Les expériences menées avec ce script permettent déjà de constater quelques surprises :
- Lorsque les deux joueurs jouent totalement au hasard, les bleus gagnent dans environ 40% des cas ; le graphe des configurations de jeu donne 42% des cas, en effet il y a 55 configurations gagnantes pour les bleus contre 76 pour les rouges.
- Lorsque les bleus gagnent c’est toujours en allant plus vite que les rouges et jamais en bloquant ceux-ci ;
- par contre lorsque les rouges gagnent, c’est dans presque le quart des cas, par blocage.
- Parmi les premiers coups possibles des rouges, aucun ne semble mener plus souvent que les autres, à une défaite. Plus précisément,
- La probabilité que les rouges aient joué la voiture du milieu sachant qu’ils ont gagné est environ 0,2. Cela peut surprendre mais en commençant par la voiture du milieu les rouges font un choix parmi 5
- Les destinations 5, 6, 7, 8 et 9 sont équiprobables, sachant que les rouges ont gagné.
- Par contre la probabilité que les rouges aient joué la voiture du milieu sachant qu’ils ont vaincu les bleus par blocage est plus élevée : environ une chance sur 4.
Cela suggère déjà un conseil pour les rouges : Commencer par mettre la voiture du milieu sur le sommet central, puis essayer à partir de là, de bloquer les bleus. Mais le jeu totalement au hasard éclaire peu sur les meilleurs choix des deux joueurs, il faut donc aller plus loin ; pour cela on a deux directions : Jouer moins au hasard (comme les joueurs humains qui reculent rarement), ou faire le graphe du jeu et repérer dans ce graphe les configurations gagnantes pour les rouges.
Jouer moins au hasard
Le problème avec les marches aléatoires sur le graphe, c’est qu’elles tendent à durer longtemps. Ceci est dû au fait que les deux joueurs reviennent souvent en arrière reproduisant ainsi une situation de jeu déjà présente. On peut donc explorer l’espace du jeu plus rapidement si chacun des joueurs joue un peu moins au hasard.
Tout d’abord, on propose de remplacer la fonction
def bleusjouent():
if not rougesgagnent():
debut,fin = choice(choixbleus())
bleus.remove(debut)
bleus.append(fin)
bleus.sort()par
def bleusjouent():
if not rougesgagnent():
debut,fin = bluechoice(choixbleus())
bleus.remove(debut)
bleus.append(fin)
bleus.sort()ce qui oblige à écrire une fonction bluechoice spéciale pour les bleus. Et de même une fonction redchoice pour les rouges, à la place de choice, mais a priori pas la même puisque les mouvements intéressants pour les rouges ne sont pas les mêmes que les mouvements intéressants pour les bleus (ils ne vont pas dans le même sens).
Avec la fonction
def bluechoice(liste):
return choice(liste)on a évidemment la même marche aléatoire qu’auparavant. Il en sera de même avec
def bluechoice(liste):
return liste[randrange(len(liste))]qui fabrique un indice aléatoire avec randrange puis prélève un élément de la liste pointé par cet indice. Maintenant, on peut modifier la fonction ci-dessus pour que les bleus choisissent plus souvent un sommet de numéro élevé qu’un retour en arrière. Pour cela, on utilise la fonction triangular qui simule une variable aléatoire de distribution affine par morceau : Elle part de 0 pour aller linéairement vers le nombre d’éléments de la liste, puis y rester (le dernier argument de la fonction est le mode de la loi de cette variable, les deux premiers sont les bornes de l’intervalle de définition). Mais pour avoir un indice de lecture dans une liste, il faut convertir ce nombre en un entier, ce qui se fait avec la fonction int :
def bluechoice(liste):
return liste[int(triangular(0,len(liste),len(liste)))]La fonction de choix aléatoire pour les rouges est aussi affine mais cette fois-ci on choisit 0 comme mode (statistiques) pour que les rouges aient tendance à aller plus vers les sommets de numéro faible (leur lieu de destination) :
def redchoice(liste):
return liste[int(triangular(0,len(liste),0))]Voici un exemple de jeu ainsi simulé [2] :

On voit que la partie ressemble beaucoup à un jeu mené entre humains plus ou moins débutants. Et encore une fois, c’est en bloquant les bleus, que les rouges gagnent relativement vite.
Pour produire des dessins animés comme ceux de cet article, et pour peu que le module graphviz soit installé, on peut utiliser le script que voici :
En augmentant la probabilité d’avancer par rapport à la probabilité de reculer, et en sélectionnant les parties les plus courtes se soldant par un blocage des bleus par les rouges, on obtient ce genre de jeu où les rouges gagnent en 25 coups :
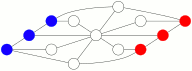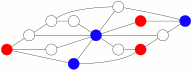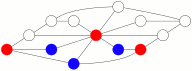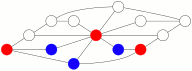
L’animation ci-dessus tourne en boucle, si on attend suffisamment longtemps. N’a-t-on pas l’impression, en la regardant, que les deux joueurs et surtout les rouges font parfois des coups subtils ?
L’inférence bayésienne n’ayant pas donné de stratégie gagnante, on doit aller plus loin vers le deep learning avec un réseau bayésien. Comme le plateau de jeu est relativement petit, on va se contenter d’un graphe du jeu.
Exploration exhaustive
Une première, et essentielle, question qui se pose, est « comment va-t-on le représenter, ce fameux graphe ? »
Avec des triplets
La recherche d’une stratégie gagnante n’est pas si simple. Puisque le jeu est relativement petit nous avons écrit un script permettant de construire la totalité des configurations de jeu possibles : 34188 au total.
Une configuration de jeu est complètement définie par les positions de Rouge, celles de Bleu et par le joueur qui doit jouer. On pourrait coder en utilisant par exemple les tuples de Python :
Ainsi
((10, 11, 12), (0, 1, 2), 0)
représente la configuration initiale, et c’est à Rouge (modélisé par 0) de jouer. Les configurations atteignables à partir de celle-là sont :
((6,10,12), (0,1,2), 1)
((7,10,11), (0,1,2), 1)
((9,10,11), (0,1,2), 1)
((5,11,12), (0,1,2), 1)
((8,11,12), (0,1,2), 1)Or « atteignable » se modélise par des arêtes dans un graphe orienté, dont voici le début :

Nous pouvons donc construire un graphe orienté de 34188 sommets et dont les arêtes représentent le passage possible d’une configuration A à une configuration B par un coup valide. En voici un extrait :
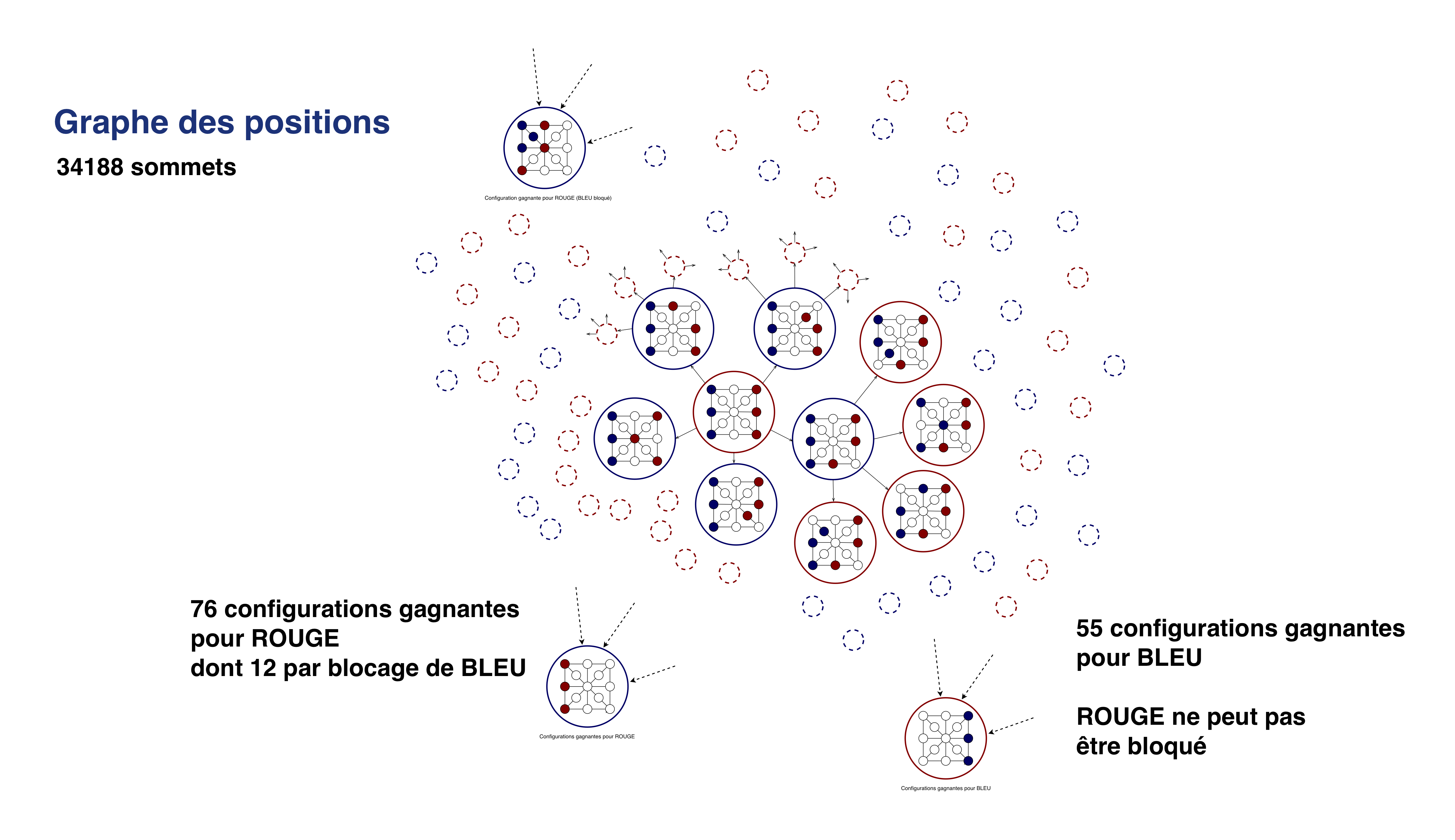
L’étude des ces 34188 configurations a révélé les 76 configurations gagnantes pour Rouge et les 55 pour Bleu. Ce qui explique dans les parties aléatoires les 42% de victoires pour Bleu contre 58% pour Rouge.
Parmi ces 76 configurations gagnantes pour Rouge il y a les 12 configurations où Bleu est bloqué (comme celle présentée sur l’animation précédente).
Dessiner le graphe en entier n’est pas très utile, on n’y verrait pas grand-chose avec 34188 sommets. C’est un problème typique des Big data, sur lesquelles il faudrait raisonner directement plutôt qu’un dessin exhaustif. Mais déjà, pour raisonner sur des Big Data, on doit d’abord se les procurer, ces « Big » Data ! Le format Json est approprié.
Python dispose d’un module json permettant de traduire de et vers une relation (mathématiques), ou « dictionnaire » en Python, ou JSON sur le ouèbe [3].
Avec des ensembles de sommets
Ce graphe a été modélisé par ses listes d’adjacences, en utilisant un dictionnaire et des ensembles (la structure de données set de Python est vraiment intéressante, nous y reviendrons à la fin de cet article) :
all_configs = { '10,11,12,0,1,2,0' :
{ '6,10,12,0,1,2,1',
'7,10,11,0,1,2,1',
'9,10,11,0,1,2,1',
'5,11,12,0,1,2,1',
'8,11,12,0,1,2,1'
},
... }Nous avons abandonné les tuples au profit des chaînes de caractères. En effet une fois ce graphe calculé, nous l’avons stocké dans un fichier texte au format de données json. 0r ce format n’accepte pas les tuples comme clé des dictionnaires. D’où le choix des str.
Il est alors très simple de stocker notre graphe dans un fichier :
import json
with open(mon_fichier.json, 'w') as f_out:
json.dump(all_configs, f_out, indent=3)Le paramètre indent est facultatif mais facilite la visualisation du fichier dans un éditeur de texte. La récupération de notre graphe est tout aussi simple [4] :
import json
with open(mon_fichier.json) as f_in:
all_configs = json.load(f_in)Le fichier final est disponible ci-dessous [5] :
Sa création repose sur un parcours en largeur du graphe dont on parlait. On part de la configuration initiale et on génère toutes les configurations atteignables à partir de celle là. Puis on traite chacune de ces configurations de la même façon et ainsi de suite. Il faut bien sûr conserver une trace des configurations visitées pour ne pas les traiter deux fois. Le processus s’arrête quand on n’a plus de configurations à traiter.
Voici le fichier ayant engendré le graphe du jeu :
Au départ nous pensions, avec ce graphe, pouvoir coder une stratégie privilégiant le choix d’une configuration qui minimiserait la distance à une configuration gagnante. Cette stratégie s’est avérée inefficace, se soldant par des parties très longues (les deux joueurs campent sur leurs positions). Lorsque Rouge adopte cette stratégie et que Bleu joue au hasard, Bleu gagne presque systématiquement : en fait Rouge change constamment d’objectif. Peut-on y voir là un clin d’œil : la persévérance paie.
Les tests effectués nous ont persuadés que la stratégie la plus efficace pour Rouge est d’essayer de bloquer Bleu plutôt que de le prendre de vitesse. Cette observation a déjà été constatée par les joueurs humains.
En codant la stratégie qui consiste à augmenter la probabilité d’avancer, on constate que Rouge gagne un peu moins souvent qu’avant (52%) et les victoires de Rouge par blocage représentent moins de 4% (contre 25% dans les parties aléatoires).
Gagner par étouffement
Comme pressenti, la stratégie consistant à vouloir réduire systématiquement les degrés de liberté de Bleu pour tenter d’aller vers une victoire par blocage, est efficace.
Avec cette stratégie, Bleu qui joue au hasard perd dans 100% des cas, et toujours par blocage. En voici un exemple :

Bien sûr, si Bleu ne joue pas au hasard, on retombe sur le problème des parties interminables et la nécessité de modifier les règles pour interdire le trop grand nombre de répétitions. On peut pour cela s’inspirer de la règle du ko (go)...
Apport de la programmation objet
Pour programmer les stratégies gagnantes à tester de manière à pouvoir s’adapter facilement à toutes situations, on a choisi le paradigme modèle-vue-contrôleur et la programmation objet que permet (entre autres) Python. Pour une initiation à la programmation objet, on peut voir cet article présentant une classe relativement simple : celle des variables de Sofus. Dans le fichier ci-dessous c’est la classe GameModel qui gère les stratégies à tester.
Nous en avons testé 4 :
- Le jeu totalement au hasard déjà vu précédemment
def alea(self):
cfg = self.config
player = self.player()
possibilities = list(self.allcfgs[cfg])
return random.choice(possibilities)- Le jeu avec loi triangulaire [6] également déjà vu (on essaye de ne pas reculer trop souvent) :
def oriented(self):
cfg = self.config
player = self.player()
possibilities = list(self.allcfgs[cfg])
possible_moves = [self.move_played(cfg, ncfg)[1] for ncfg in possibilities]
combine = list(zip(possibilities, possible_moves))
combine.sort(key=lambda e: e[1], reverse=bool(player))
nb = len(combine)
return combine[int(random.triangular(0,nb,0))][0]- Le jeu consistant à essayer d’occuper le sommet central et de bloquer l’adversaire
def less_liberties(self):
p = self.player()
cfg = self.config
possibilities = [(new_cfg, self.liberties(new_cfg, 1 - p))
for new_cfg in self.allcfgs[cfg]]
nb_liberties = INF
best_cfg = None
for ncfg, liberties in possibilities:
if not self.losing(ncfg) and (nb_liberties > liberties\
or nb_liberties == liberties and 6 in self.positions(ncfg, p)):
best_cfg = ncfg
nb_liberties = liberties
if not best_cfg:
best_cfg = self.alea()
return best_cfg- Le jeu privilégiant les coups qui ont été gagnants dans le passé (modélisation de l’apprentissage) :
def bayesien(self):
p = self.player()
cfg = self.config
possibilities = list(self.allcfgs[cfg].items())
pour_tirage = get_intervalles(possibilities)
try:
cfg_choisie = tirage(pour_tirage)
except:
cfg_choisie = random.choice(pour_tirage)[0]
return cfg_choisieCe qui est intéressant à ce stade c’est de voir comment évoluent dans le temps (apprentissage) les victoires d’une stratégie contre une autre.
Voici l’évolution temporelle des parties jouées entre la stratégie bayesien et la stratégie less_liberties. On constate que la première finit par gagner souvent contre la seconde (phénomène d’apprentissage) :
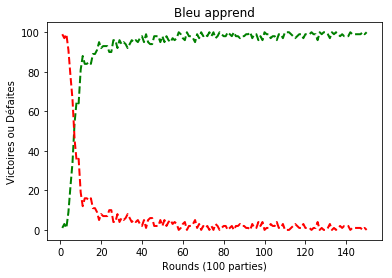
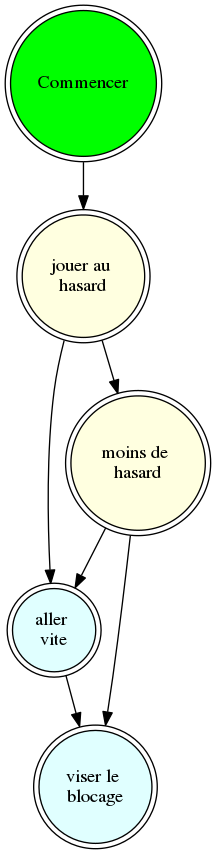
Voici le graphe du parcours effectué :
En guise d’exercice, vous pouvez essayer, avec les outils présentés ici, de chercher qui gagne à la version étendue du jeu, et comment (existe-t-il une stratégie gagnante pour l’un des joueurs ?)
Voici le jeu étendu :
IA sans Python
Le logiciel ludii permet de programmer tous les jeux abstraits (et d’y faire jouer des IA). Dans ludii, les plateaux de jeu sont des graphes. Voici le jeu de cet article programmé en ludii :
(game "Parkings"
(players 2)
(equipment
{
(board
(graph
vertices: {
{0 0} {2 0} {4 0} {1 1} {3 1} {0 2} {2 2} {4 2}
{1 3} {3 3} {0 4} {2 4} {4 4}
}
edges: { {0 1} {1 2} {0 3} {2 4} {0 5} {1 6} {2 7} {3 6} {4 6}
{5 6} {6 7} {6 8} {6 9} {5 10} {6 11} {7 12}
{8 10} {9 12} {10 11} {11 12} }
)
use: Vertex
)
(piece "Ball" Each (move Step (to if:(is Empty (to)))))
(regions P1 (sites Bottom))
(regions P2 (sites Top))
}
)
(rules
(start
{
(place "Ball1" (sites Bottom))
(place "Ball2" (sites Top))
}
)
(play (forEach Piece))
(end (if
(or (no Moves Next)
(or
(and ("AllOwnedPiecesIn" (sites Top)) (is Mover P1))
(and ("AllOwnedPiecesIn" (sites Bottom)) (is Mover P2))
)
)
(result Mover Win)))
)
)
(metadata
(graphics {
(piece Colour P2 "Ball" fillColour:(colour Blue))
(piece Colour P1 "Ball" fillColour:(colour Red))
})
)Alors, si le joueur aux pions rouges utilise un élagage alpha-bêta alors que l’autre joueur joue au hasard, cela peut prendre un peu de temps pour gagner :
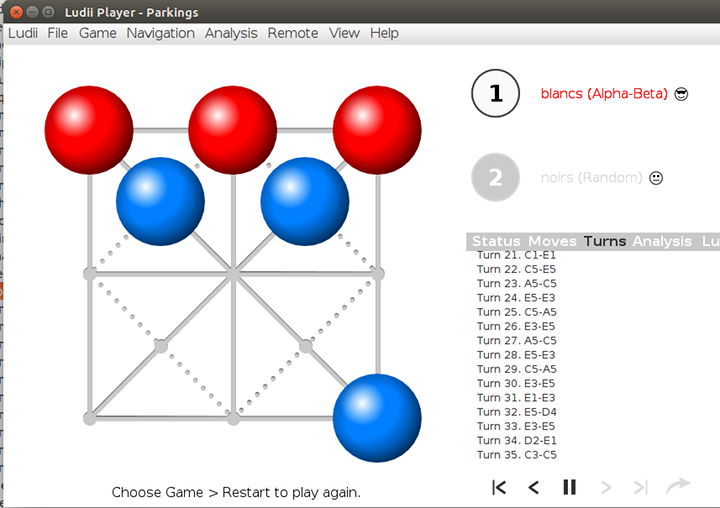
Mais si le joueur aux pions bleus joue vraiment mal, la partie est plus courte :
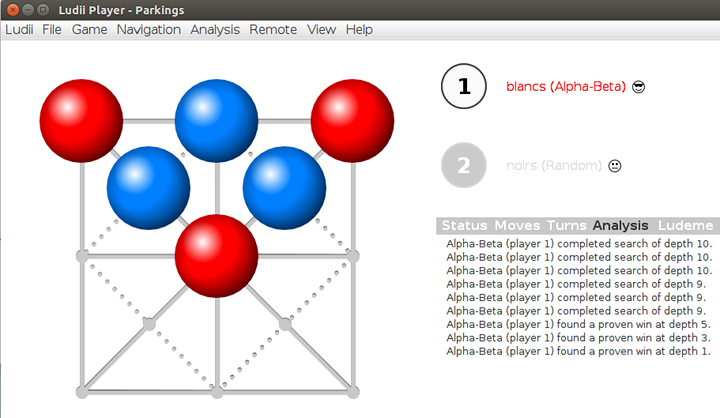
On remarque que le premier joueur a trouvé une stratégie gagnante vers la fin, et n’a pas eu de grande profondeur à explorer.
évolution du jeu
Pour éviter les parties infinies, rien de tel qu’un variant. La volonté de simuler le comportement de paquets TCP (qui vieillissent à chaque mouvement) a mené à cette version où les joueurs (pions humains sur le graphe géant) portent des brassards (ou des cartes) et cèdent un brassard à chaque mouvement. Lorsqu’un joueur n’a plus de brassard, il est bloqué. Le nombre total de brassards est donc un variant et garantit qu’une partie dure 18 coups maximum.
Souvent, la partie dure exactement 18 mouvements et aucune équipe n’est au bout lorsque tout le monde a consommé ses 3 mouvements. Comment alors départager les joueurs ?
Le critère choisi est que l’équipe globalement la plus proche de sa ligne d’arrivée est gagnante. Mais avec cela, lorsque les joueurs jouent au mieux, chacun finit à distance totale 1 de sa ligne d’arrivée et il y a ex æquo. Un élève de terminale NSI propose alors qu’on puisse (toujours en abandonnant un brassard) passer son tour. Dale Walton [10] propose le même aménagement de la règle du jeu. Cela produit le script ludii suivant :
(game "Brassards"
("TwoPlayersNorthSouth")
(equipment
{
(board
(graph
vertices: {
{0 0} {2 0} {4 0} {1 1} {3 1} {0 2} {2 2} {4 2}
{1 3} {3 3} {0 4} {2 4} {4 4}
}
edges: { {0 1} {1 2} {0 3} {2 4} {0 5} {1 6} {2 7}
{3 6} {4 6} {5 6} {6 7} {6 8} {6 9} {5 10}
{6 11} {7 12} {8 10} {9 12} {10 11} {11 12}
}
)
use: Vertex
)
(piece "DiscFlat" Each
(if
(> (count Stack at:(from)) 1)
(or
(move Select
(from)
)
(move Step
(to if:(is Empty (to)))
stack:True
)
(then (remove (last To) ))
)
)
)
}
)
(rules
(start
{
(place Stack "DiscFlat1" (sites Bottom) count:4)
(place Stack "DiscFlat2" (sites Top) count:4)
}
)
(play (forEach Piece))
(end (if
(or (no Moves Next)
(or
(and ("AllOwnedPiecesIn" (sites Top)) (is Mover P1))
(and ("AllOwnedPiecesIn" (sites Bottom)) (is Mover P2))
)
)
(byScore
{
(score P1
(+ (results
from: (sites Occupied by:P1)
to:0
(count Steps (from) (sites Top))
)
)
)
(score P2
(+ (results
from: (sites Occupied by:P2)
to:0
(count Steps (from) (sites Bottom))
)
)
)
}
misere:True
)
)
)
)
)
(metadata
(info
{
(description "The game of the armbands is played on a graph, with a North and a South Region. At the beginning, every piece is on the player's region. The first one who has his pieces in the opposite region, wins the game. But on every move, the player looses one armband (the piece had 3 armbands at the beginning). When a piece has no armband left, it can not move anymore. If a player has no move, he looses the game. When no player has any move, the game is ended, and the winner is the one whose pieces are the nearest from the enemy's region ")
(version "1.0.0")
(classification "board/race")
(credit "Alain Busser")
(origin "This game was created on Reunion Island in 2020")
}
)
(graphics {
(piece Colour P2 "DiscFlat" fillColour:(colour Blue))
(piece Colour P1 "DiscFlat" fillColour:(colour Red))
})
)Avec ça, le jeu semble présenter une stratégie gagnante pour celui qui joue en premier :

Cependant, il est difficile de deviner où on va, puisqu’il est clair qu’on n’approche pas beaucoup de la ligne d’arrivée :
- distance 2+1+1=4 pour les rouges
- distance 1+2+2=5 pour les bleus

Commentaires