Voici le vocabulaire utilisé dans cet article :
| type | nom |
bool |
booléen (ou proposition logique) |
bool -> bool |
fonction booléenne |
int -> bool |
prédicat |
int |
entier naturel |
int -> int |
suite d’entiers |
Tables de multiplication
De même, la multiplication est une opération binaire (d’arité 2) dont une table de valeurs est bidimensionnelle : la table de Pythagore. La curryfication fait passer d’un tableau de dimension 2 à une liste de fonctions linéaires (comme les bâtons de Neper). Ce point de vue se retrouve dans l’expression « la table de 4 » qui désigne l’une des colonnes de la table de Pythagore. Par exemple pour retrouver 6×4, il suffit de chercher le 6e terme de la suite des multiples de 4, et cela ne nécessite que de
- savoir compter jusqu’à 6,
- connaître la table de 4.
Et quand je dis « connaître la table de 4 » il peut s’agir d’un algorithme permettant de la reconstruire, par exemple en écrivant les chiffres 0,4,8,2,6 aussi souvent que nécessaire comme chiffres des unités et ne changer de chiffre des dizaines que lorsqu’on passe de 8 à 2 ou de 6 à 0. Bref, une connaissance procédurale de certaines colonnes de la table de Pythagore permet de retrouver celle-ci sans avoir à tout de suite apprendre les 100 valeurs qui sont inscrites dedans.
Cette idée (compter 6 fois de 4 en 4, plus généralement a fois de b en b) est d’ailleurs à la base de la définition récursive de la multiplication par Peano :
Version Ocaml
# let rec produit a b =
match a with
| 0 -> 0
| _ -> b + produit (a-1) b
;;
val produit : int -> int -> int = <fun>
# produit 6 4;;
- : int = 24Version Haskell
Prelude> let produit a b
| a==0 = 0
| otherwise = b+produit (a-1) b
Prelude> :t produit
produit :: (Eq a, Num a, Num a1) => a -> a1 -> a1
Prelude> produit 6 4
24Ocaml et Haskell n’infèrent pas le type de la multiplication de la même manière : pour Ocaml, a priori, les nombres à multiplier sont entiers (jusqu’à plus ample informé) et le produit aussi. Alors que pour Haskell, les deux facteurs doivent être des nombres (de types a et a1) et le produit est du même type que le second facteur, mais il faut aussi que le premier facteur puisse être comparé avec 0.
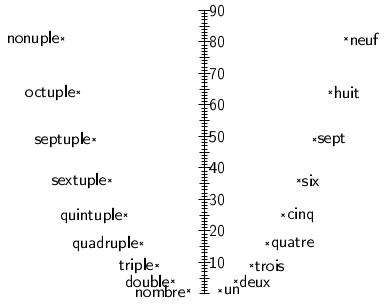
L’idée de voir la table de Pythagore comme une collection de fonctions se retrouve
- dans l’usage du pluriel « Les tables de multiplication »
- dans le mot « livret » utilisé dans certains pays francophones pour désigner ladite table de Pythagore.
Chaque colonne de la table de Pythagore est en fait un tableau de valeur d’une fonction (identité, double, triple etc) et j’ai fabriqué un vrai livret où chaque page représente non pas un tableau, mais un diagramme sagittal :

Il peut être intéressant de tester l’utilisation de ce livret pour enseigner les tables de multiplication notamment à des élèves dys.
D’après l’Encyclopédie de d’Alembert et Diderot, la connaissance de la table de Pythagore était jugée indispensable au XVIIIe siècle :
il est absolument nécessaire que ceux qui apprennent l’Arithmétique, sachent par cœur les différentes multiplications contenues dans cette table
La nécessité de chercher l’intersection d’une ligne et d’une colonne était également connue des encyclopédistes :
Exemple. Supposé qu’il faille savoir le produit de 6 multipliés par 8, cherchez le chiffre 6 dans la premiere colonne horisontale, qui commence par 1 ; ensuite cherchez le chiffre 8, dans la premiere colonne perpendiculaire qui commence également par 1.
Le quarré ou la cellule de rencontre, c’est-à-dire où la colonne horisontale de 6 se rencontre avec la colonne perpendiculaire de 8, contient le produit qu’on cherche, savoir 48.
Comme je l’avais écrit plus haut, le fait de nommer un concept aide à réifier ce concept. Les fonctions qui forment les colonnes de la table de Pythagore possèdent des noms numéraux en l’occurence) :
En Ocaml
# let double x = 2*x;;
val double : int -> int = <fun>
# let triple x = 3*x;;
val triple : int -> int = <fun>
# let quadruple x = 4*x;;
val quadruple : int -> int = <fun>
# let quintuple x = 5*x;;
val quintuple : int -> int = <fun>
# let sextuple x = 6*x;;
val sextuple : int -> int = <fun>
# let septuple x = 7*x;;
val septuple : int -> int = <fun>
# let octuple x = 8*x;;
val octuple : int -> int = <fun>
# let nonuple x = 9*x;;
val nonuple : int -> int = <fun>
# sextuple 4;;
- : int = 24
# quadruple 6;;
- : int = 24En Haskell
Prelude> let double = (*) 2
Prelude> let triple = (*) 3
Prelude> let quadruple = (*) 4
Prelude> let quintuple = (*) 5
Prelude> let sextuple = (*) 6
Prelude> let septuple = (*) 7
Prelude> let octuple = (*) 8
Prelude> let nonuple = (*) 9
Prelude> let décuple = (*) 10
Prelude> quadruple 6
24
Prelude> sextuple 4
24L’idée de curryfier la multiplication ne date pas de Curry, puisque vers l’an 1000, Bernelin de Paris y fait allusion dans un manuscrit sur l’abaque de Gerbert. Voici un livret réumant sa vision de l’apprentissage verbal des tables de multiplication :
Et le source de ce livret :

Arbres syntaxiques
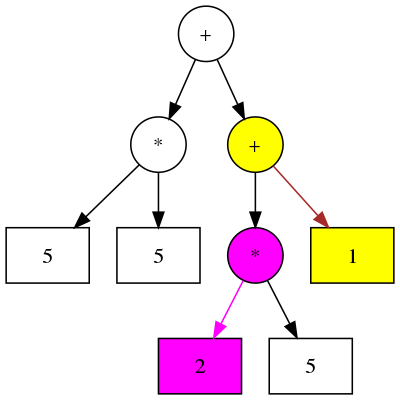
La curryfication se voit bien dans un arbre syntaxique : pour une opération d’arité 2 l’arbre est binaire, et la curryfication le rend monodimensionnel :

La figure 4 de Shannon
Dans an investigation on the laws of thought, George Boole écrivait ceci :
Suppose, then, such knowledge is to the following effect, viz., that the members of that portion which possess the property x, possess also a certain property u, and that these conditions united are a sufficient definition of them. We may then represent that portion of the original class by the expression ux (II. 6). If, further, we obtain information that the members of the original class which do not possess the property x, are subject to a condition v, and are thus defined, it is clear, that those members will be represented by the expression v (1 − x). Hence the class in its totality will be represented by
ux + v (1 − x).
Pour une fonction booléenne f d’arité 1, Boole donne le développement suivant :
f (x) = f (1) x + f (0) (1 − x)
On peut montrer cette formule par une table de vérité, comme l’écrit Boole :
x regarded as a quantitative symbol admits only of the values 0 and 1, and for
each of these values the development f (1) x + f (0) (1 − x), assumes the same value as the function f (x).
Ensuite, Boole généralise à des opérations (d’arité 2 dans un premier temps) booléennes, avec ce développement :
f (x, y) = f (1, y) x + f (0, y) (1 − x) ;
puis à trois variables booléennes :
f (x, y, z) = f (1, 1, 1) xyz + f (1, 1, 0) xy (1 − z) + f (1, 0, 1) x (1 − y) z
+ f (1, 0, 0) x (1 − y) (1 − z) + f (0, 1, 1) (1 − x) yz
+ f (0, 1, 0) (1 − x) y (1 − z) + f (0, 0, 1) (1 − x) (1 − y) z
+ f (0, 0, 0) (1 − x) (1 − y) (1 − z)
En 1938, Shannon trouve le moyen de représenter par un circuit électronique ce résultat de Boole, appelé aujourd’hui algorithme de Quine-McCluskey.
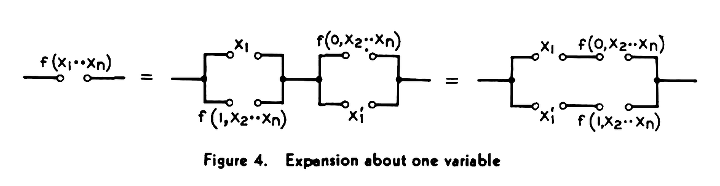
En fait il s’agit de curryfication des opérateurs booléens...
La programmation objet et l’arité 2
Les langages de programmation objet permettent de définir des opérations d’arité 2, et ensuite de les utiliser de manière infixe. Cela permet d’utiliser ces langages pour verbaliser le cours de mathématiques comme le préconisait Seymour Papert, en laissant l’enfant apprendre par les explications qu’il donne à une machine. Dans cette partie finale (un peu hors sujet) on va comparer les façons de faire avec plusieurs de ces langages. Avec l’exemple de l’addition des vecteurs.
La programmation objet de Python permet de définir une méthode qui sera appelée par un « + » infixe, c’est-à-dire de définir sa propre addition et de l’appeler simplement en écrivant le signe « + » entre deux opérandes. Il en est de même pour Ruby :
Les langages de programmation objet comme Python et Ruby permettent donc de construire un savoir algébrique en permettant aux élèves d’inventer leurs propres opérations et de calculer avec ces opérations. On peut voir aussi
- l’exemple des fractions en Python
- celui des extensions quadratiques
- celui des quaternions en Python et en Ruby
Le calcul matriciel (en particulier avec des matrices de RegEx) et les fractions de Farey sont des exemples restant à explorer.

Commentaires