
Problème 1 : Points proches dans le plan
Points
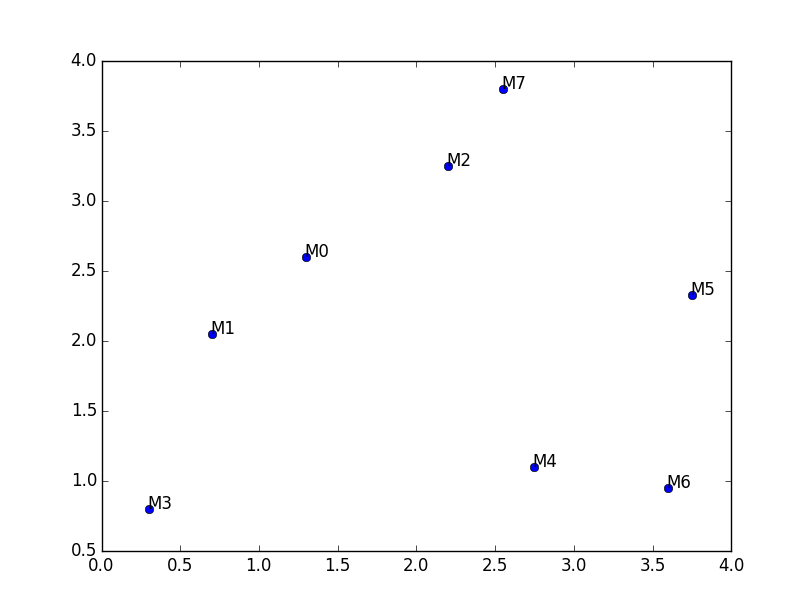
Avec ces coordonnées
coords_x = [1.3,0.7,2.2,0.3,2.75,3.75,3.6,2.55]
coords_y = [2.6,2.05,3.25,0.8,1.1,2.33,0.95,3.8]on a le nuage de points de l’énoncé :
On suppose qu’on a une variable globale
n = len(coords_x)
Clusters
Dans la suite, un sous-ensemble de points est appelé un cluster. Par exemple, le nuage de points de l’énoncé devient le cluster suivant :
liste_x = [3,1,0,2,7,4,6,5]
liste_y = [3,6,4,1,5,0,2,7]
cluster_a = [[liste_x, liste_y]]Alors que les points à gauche de la ligne verte pointillée forment le cluster
cluster_b = [ [3,1,0,2,7,4],
[3,4,1,0,2,7] ]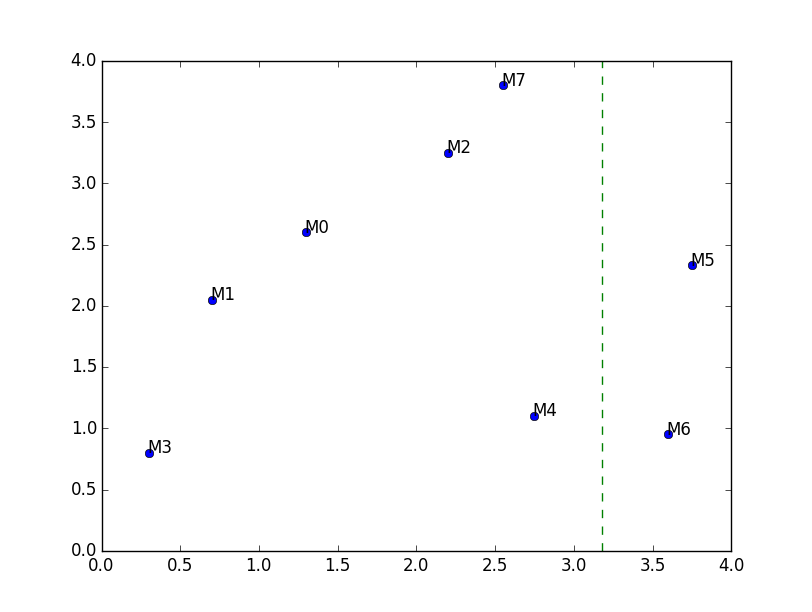
Récursivité

Les algorithmes de cette partie sont de Serge Bays.
Question 14
On considère le point dont l’abscisse est la médiane des abscisses (il est sur le trait rouge) et dont l’ordonnée est la moyenne des ordonnées de M1 et M2. On considère le rectangle centré sur ce point, de largeur 2×d0 et de hauteur d0 (ce rectangle contient donc M1 et M2). Si ce rectangle contenait plus de 8 points, deux d’entre eux seraient nécessairement du même côté de la ligne rouge, et à distance inférieure à d0. Ce qui est contraire à la définition de d0.

Donc il y a au maximum, dans le sens des ordonnées croissantes, 6 points entre M1 et M2 dans la bande verte (les 8 points maximum en question, moins M1 et M2).
Problème 2 : Composantes connexes et biconnexes
Graphes
Voici les graphes de l’énoncé, au format Nirina974 :
Gex :
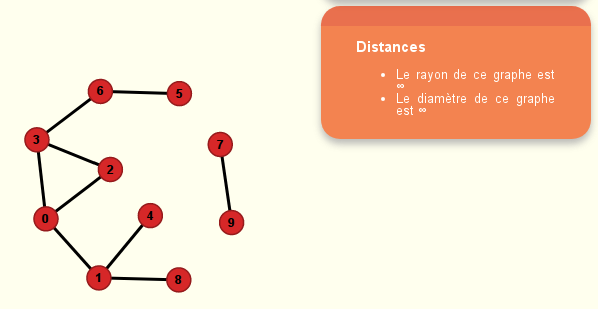
(on voit qu’il n’est pas connexe puisque tous ses sommets sont d’excentricité infinie)
G’ex :

Celui-là par contre est connexe. Mais on verra qu’il n’est pas biconnexe.
BDD
Les corrigés suivants sont de Rafael Lopez, d’Orsay.
connexes
Question 26
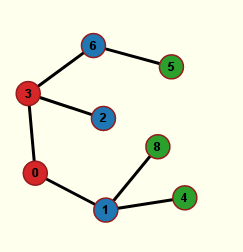
Le parcours renvoie une liste d’arbres (c’est-à-dire d’objets de la classe Arbre). Une telle liste modélise une forêt. Le parcours est un parcours en profondeur. Il construit la forêt couvrante que voici :
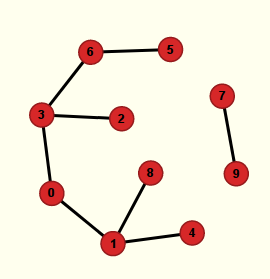
Cette forêt n’est pas connexe, mais chacune de ses composantes connexes est un arbre. Le plus petit de ces arbres est ⑦-⑨ et tout le reste forme cet arbre :
biconnexes
Pour Internet, les graphes biconnexes sont intéressants parce qu’une panne d’un seul routeur ne suffit pas à empêcher le réseau de fonctionner.

Question 34
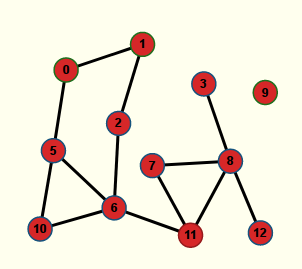
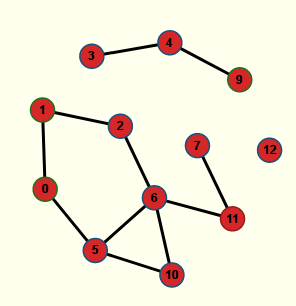
Avec Nirina974 il est aisé de voir quels sont les points d’articulation du graphe : il suffit d’enlever (puis remettre) l’un après l’autre les sommets et regarder si le graphe est encore connexe, ou pas (cela se voit à la couleur, uniformément rouge si le graphe n’est plus connexe). Les points d’articulation sont donc
- le sommet 4 :
- le sommet 6 :

- le sommet 8 :
- le sommet 11 :
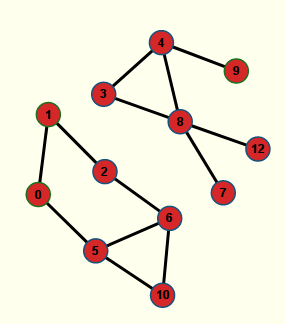
G’ex possède donc 4 points d’articulation. On en déduira par la suite, qu’il n’est pas biconnexe.
algorithme
Question 39
Le parcours du graphe à partir de ⓪ donne l’arbre couvrant suivant :
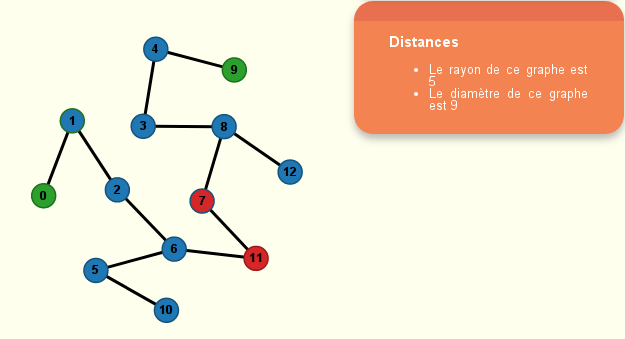
et la liste prefixe suivante :
[1, 2, 3, 10, 11, 5, 4, 8, 9, 12, 6, 7, 13]
Ce qui correspond à ces préfixes :
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 1 | 2 | 3 | 10 | 11 | 5 | 4 | 8 | 9 | 12 | 6 | 7 | 13 |
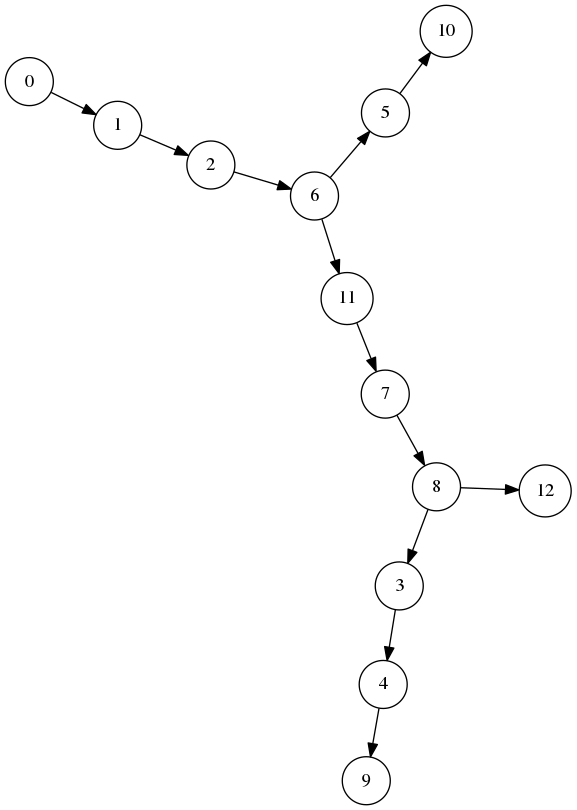
Question 41
Pour rappel, voici le graphe :
et ses ord (prefixe minimal parmi les voisins des descendants) :

On constate que
- 9, qui est le fils de 4, est d’ordre 11 qui est le préfixe de 4.
- 11, qui est un des fils de 6, est d’ordre 4 qui est le préfixe de 6.
- 7, qui est le fils de 11, est d’ordre 7 qui est le préfixe de 11.
- 3, qui est un des fils de 8, est d’ordre 9 qui est le préfixe de 8.
En dehors de ces sommets qui sont les points d’articulation, seule la racine 0 a une propriété similaire : son fils 1 est d’ordre 1 qui est le préfixe de 0.
Question 44
Comme chaque point d’articulation sépare deux composantes biconnexes, on est tenté de regarder à quoi ressemble le graphe auquel on a enlevé les points d’articulation :
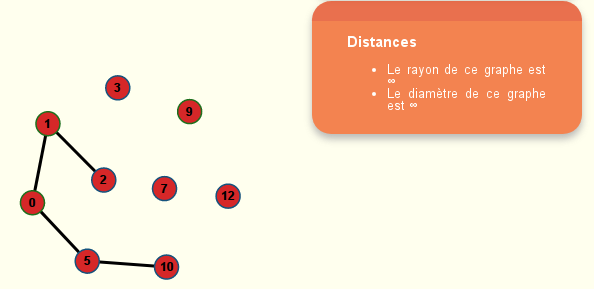
On voit qu’il y a 5 composantes connexes et chacune correspond à une composante biconnexe du graphe de départ. Où est passée la 6e composante biconnexe ?
En fait l’arête 6-11 (une composante biconnexe) joint deux points d’articulation, elle a donc disparu lorsque ses extrémités ont été supprimées.
On suggère donc cet algorithme :
- calculer les points d’articulation
- calculer le graphe privé des points d’articulation
- pour chacune des composantes connexes de ce graphe, remettre le point d’articulation qui y était : cela donne une composante biconnexe du graphe de départ
- chercher les arêtes joignant deux points d’articulation : ce sont elles aussi des composantes biconnexes.
Cet algorithme est de Hopcroft et Tarjan en 1973 :


Commentaires