
Sujets
On propose ici
- un sujet sur les PPAC, inspiré de celui de l’X 2010
- un sujet sur le transport d’informations dans un arbre, inspiré de celui de l’X 2011
- un sujet sur la représentation des entiers sous forme d’arbres, inspiré de celui de l’ENS 2002
- un sujet sur les arbres de décision, inspiré de celui de Centrale 2013
- l’exercice 3 du sujet 0
Parents
Un arbre est un graphe, une façon naturelle de le modéliser est celle des listes d’adjacence :
- Un dictionnaire qui, à chaque nœud de l’arbre, associe la liste de ses enfants,
- ou une liste de listes (d’adjacence) si les clés du dictionnaire sont des entiers successifs.
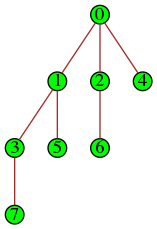
Par exemple l’arbre du sujet X 2010 :
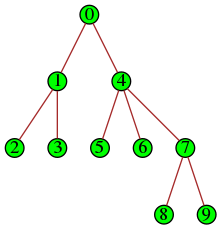
peut être modélisé en Python par un dictionnaire (voir l’onglet suivant) ou cette liste de listes :
[ [1,4],
[2,3],
[],
[],
[5,6,7],
[],
[],
[8,9],
[],
[]]Le sujet Centrale 2000 introduit une nouvelle façon de représenter les arbres :

Ce sujet évoque une fonction père qui, à tout nœud (sauf la racine), associe son unique parent (ou « père »). Il s’agit d’une fonction partielle puisque la racine n’a pas de père. Mais comme l’ensemble des nœuds de l’arbre est fini, cette fonction père est entièrement déterminée par son tableau de valeurs. Par exemple pour l’arbre du sujet X 2010, le tableau des pères est :
| nœud | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| père | aucun | 0 | 1 | 1 | 0 | 4 | 4 | 4 | 7 | 7 |
En Python on le code par
parent = [None,0,1,1,0,4,4,4,7,7]
Cette représentation est plus concise que la représentation traditionnelle par liste d’enfants, parce que, si chaque nœud (sauf les feuilles) peut avoir plusieurs enfants, il n’a qu’un seul parent. Par contre certains algorithmes sont plus faciles à mettre en œuvre sur la représentation traditionnelle.
Avec cette représentation par liste de parents, il est aisé de la racine de l’arbre.
La notion d’ancêtres mène assez naturellement à celle d’ancêtres communs, à laquelle l’onglet suivant est consacré.
PPAC
Les ancêtres communs (AC) de deux nœuds a et b d’un arbre G forment une liste :
def AC(a,b,G):
return [s for s in G if est_ancetre(s,a,G) and est_ancetre(s,b,G)]Parmi tous ces ancêtres communs, le plus petit est par définition celui qui est le plus éloigné de la racine. La notion de plus petit ancêtre commun est assez régulièrement abordée en CPGE, comme un outil servant à résoudre d’autres problèmes, ou en liaison avec la bio-informatique (notion d’arbre phylogénétique). Mais au concours Polytechnique de 2010, c’était le thème majeur du sujet :
Voici le sujet qui a été donné en devoir maison aux élèves de terminale NSI du lycée Roland-Garros :
Et voici le devoir rendu par un des élèves au format html (choix spontané) :

BioPython
Le format Newick
L’arbre ci-dessus peut être décrit par une expression parenthésée de ce genre :
((f2,f3),(f5,f6,(f8,f9)));
On constate que seules les feuilles sont nommées, on verra plus bas pourquoi.
En sauvegardant le résultat sous le nom ppac.dnd on peut créer l’arbre dans BioPython en faisant
from Bio import Phylo
tree = Phylo.read("ppac.dnd","newick")Voici le fichier Newick :

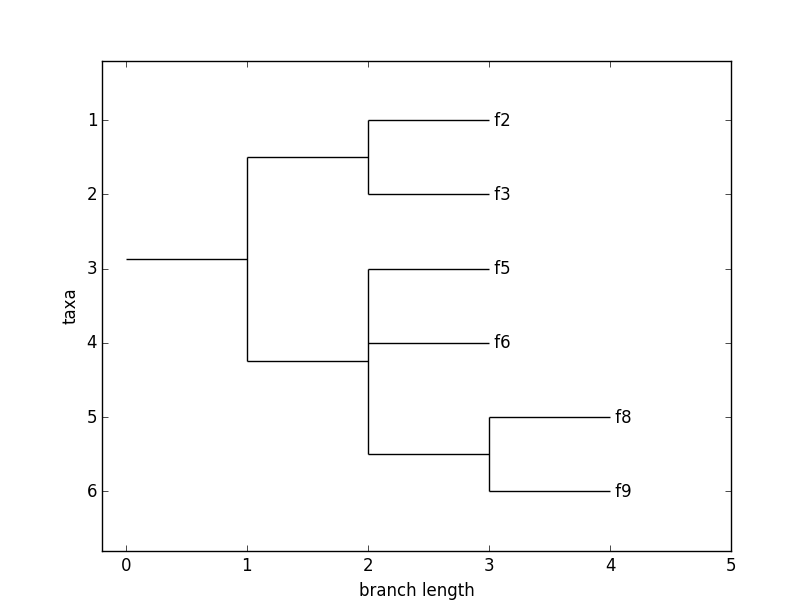
Pour chercher le plus proche ancêtre commun aux taxons numéros 5 et 8, on peut tenter un
ppac = tree.common_ancestor({"name":'f5'}, {"name":'f8'})
print(ppac)Mais dans ce cas on obtient
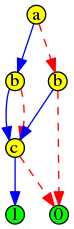
Cladece qui n’est pas très explicite : cela revient à dire que le plus proche ancêtre commun est un nœud de l’arbre (ne possédant pas de nom), ce dont se doutait un peu. Pour le dessiner, on propose de le colorier en rouge dans l’arbre tree et de dessiner la nouvelle version de cet arbre :
ppac.color='red'
Phylo.draw(tree)ce qui donne l’affichage suivant :
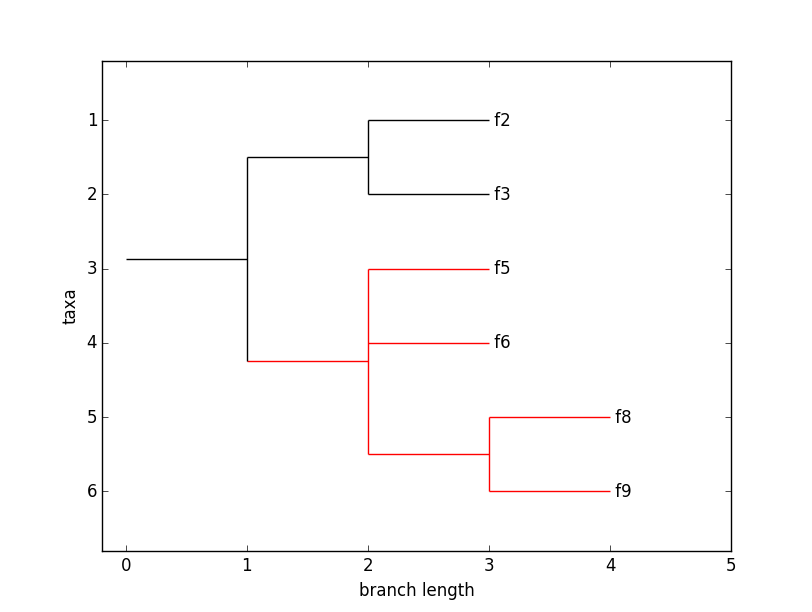
Comme on le voit, BioPython ne fait pas la distinction entre un arbre et un nœud de l’arbre.
Clades anonymes
Pourquoi les nœuds internes de BioPython n’ont-ils pas de nom ?
La réponse est assez simple à deviner : ils sont trop nombreux pour les nommer. Voici un exemple tiré du monde réel :

Question d’un élève : alors l’Homme descend du Bonobo ? Réponse : non, en fait il y a un ancêtre commun à l’Homme et au Bonobo, ou plus précisément, un ancêtre commu à l’Homme et à l’ancêtre commun au Bonobo et au Chimpanzé.
C’est l’existence de ces ancêtres communs qui est importante, pas leur nom.
Diffusion
Le sujet X 2011 portait sur la diffusion d’un message dans un arbre, à partir de la racine :
Arbres binomiaux
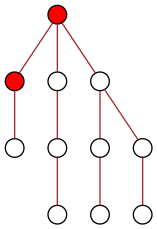
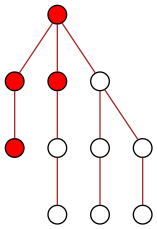
La diffusion est optimale lorsque l’arbre est dit binomial, c’est-à-dire lorsqu’il a une des formes suivantes :


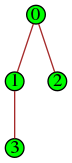

Cette structure est définie récursivement, ce qui lui donne son intérêt pour l’exercice. On remarque que la taille d’un arbre binomial est une puissance de 2.
Origine de l’exercice
En fait il s’agit de l’exercice 49 du chapitre 3 du livre de Jeff Erickson. Voici le chapitre 3 :
L’exercice 49, comme le suggère le titre du chapitre, se résout par la programmation dynamique. On y demande non pas comment diffuser le message, mais seulement le temps minimum que ça prendra.
La programmation dynamique est au programme de terminale.
On a un arbre (pas nécessairement binaire) sur lequel on doit diffuser une information à tous les nœuds. Au début seule la racine dispose de l’information :

Mais à un instant donné, un nœud ne peut diffuser l’information qu’à un seul de ses enfants. Au bout du temps t=1, seuls deux nœuds disposent alors de l’information, la racine et un de ses enfants :
La situation s’améliore ensuite puisque chacun des deux nœuds peut diffuser l’information à un (autre) de ses enfants :
Au temps t=3, la racine diffuse l’information au seul de ses enfants qui n’était pas encore au courant, et lui passe en quelque sorte le relais :
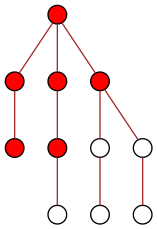
Au temps t=4, seule la partie droite de l’arbre est encore à traiter :
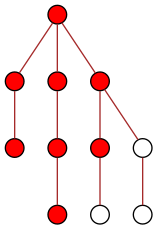
Cela permet au temps t=5 de diffuser l’information à deux nœuds en même temps (venant de leurs pères respectifs) :
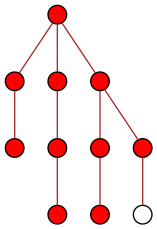
Et au temps t=6, tous les nœuds de l’arbre disposent de l’information :
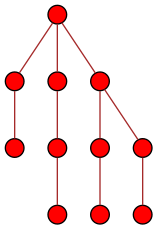
On peut faire mieux
Sur le même arbre, il y a un moyen de diffuser plus rapidement l’information, en commençant par l’enfant ayant le plus de descendants :
Au temps t=0 la situation est la même, avec un seul nœud (la racine) disposant de l’information :

Au temps t=1, là encore, seuls deux nœuds disposent de l’information :
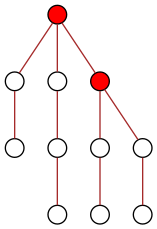
Au temps t=2, là encore, 4 nœuds disposent de l’information :
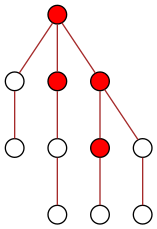
Mais au temps t=3 il y a 8 nœuds qui disposent de l’information :
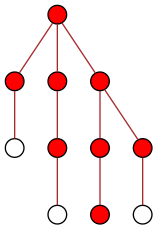
Ce qui permet de finir au temps t=4 :

Peut-on faire mieux ?
À chaque étape, les nœuds qui disposent déjà de l’information, ne peuvent la donner qu’à un de leurs enfants maximum. Alors si on note un le nombre de nœuds disposant de l’information au temps n, on sait que
- u0=1 (seule la racine est au courant au temps t=0
- un+1≤2×un
On en déduit (par récurrence) que le nombre de nœuds informés au temps n est majoré par 2n et donc que le temps nécessaire pour diffuser l’information à tout l’arbre est minoré par log2(T) où T désigne la taille de l’arbre (nombre de nœuds) et log2 la fonction qui, à un entier, associe le nombre de chiffres binaires de son écriture.
Ce minimum est atteint sur un arbre binomial, comme le montre cet exemple :
| Temps | arbre |
| 0 | 
|
| 1 | 
|
| 2 | 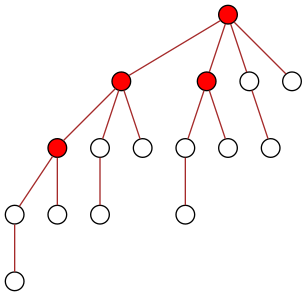
|
| 3 | 
|
| 4 | 
|
Noter que pour un arbre binaire complet, le temps nécessaire est le double de la hauteur de l’arbre, soit le double du minimum log2(T).
Entiers
Le sujet ENS 2002 portait sur le théorème de Goodstein :
Ce qui est intéressant avec ce sujet, c’est qu’il propose entre autres une manière de représenter les entiers naturels par des arbres binaires. Et même plusieurs puisque l’arbre obtenu dépend de la base. Ici on va le faire en base 2 seulement. Voici les représentations obtenues :
| Nombre | Arbre binaire |
| 0 | 
|
| 1 | 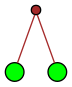
|
| 2 | 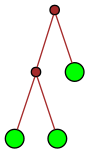
|
| 3 | 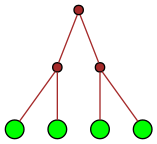
|
| 4 | 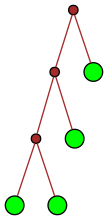
|
| 5 | 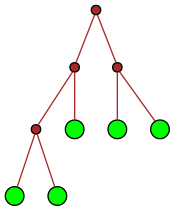
|
| 6 | 
|
| 7 | 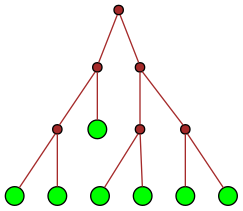
|
| 8 | 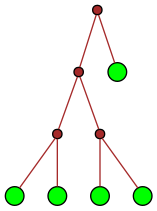
|
| 9 | 
|
| 10 | 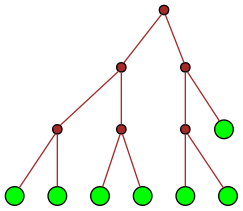
|
| 11 | 
|
| 12 | 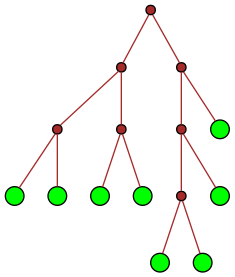
|
| 13 | 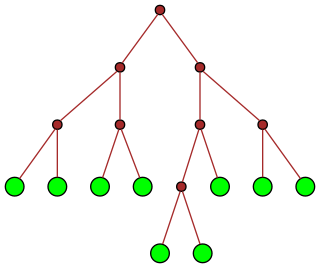
|
| 14 | 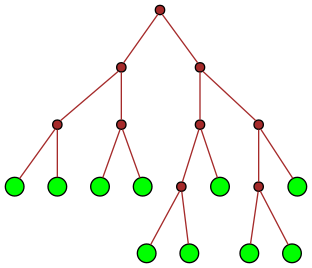
|
| 15 | 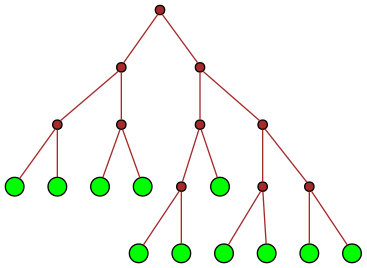
|
| 16 | 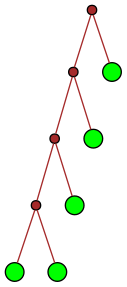
|
| 17 | 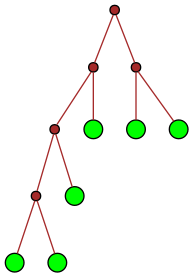
|
| 18 | 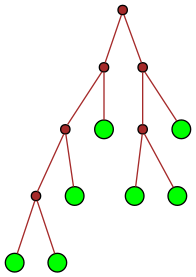
|
| 19 | 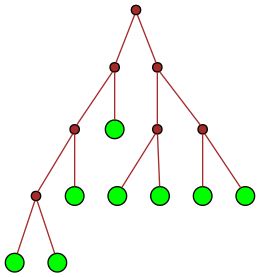
|
| 20 | 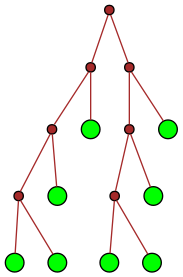
|
| 21 | 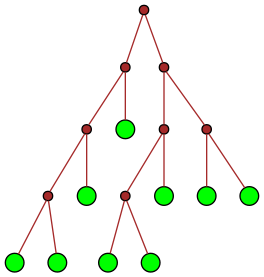
|
| 22 | 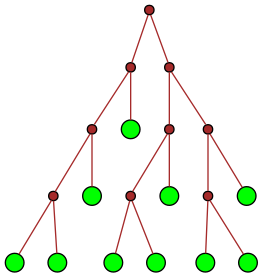
|
| 23 | 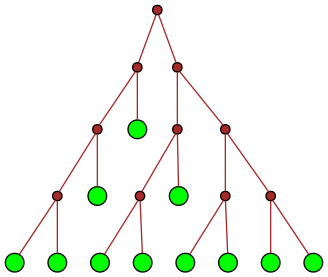
|
| 24 | 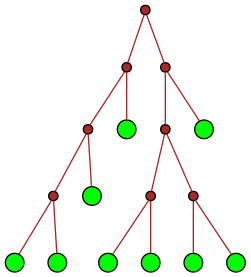
|
| 25 | 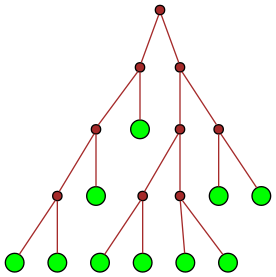
|
| 26 | 
|
| 27 | 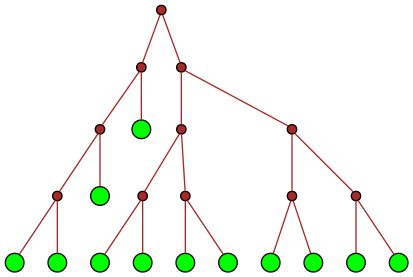
|
| 28 | 
|
| 29 | 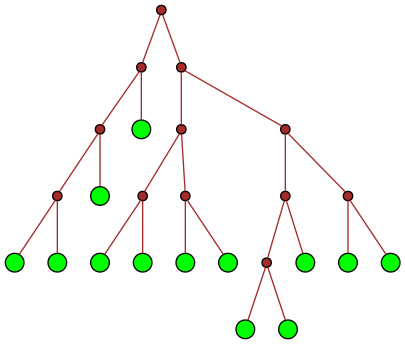
|
| 30 | 
|
| 31 | 
|
| 32 | 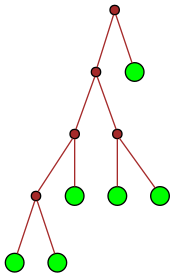
|
Ce sujet est en relation avec le jeu Hydra décrit ici :
Décision
Le sujet Centrale 2013 portait sur la notion d’arbre de décision. Un tel arbre est un arbres binaire. Le fils gauche représente la valeur vrai et le fils droit représente la valeur faux :
L’exemple introductif est intéressant :
- on note e la proposition « le candidat a réussi l’examen »
- on note a la proposition « le candidat a été assidu »
- on note r la proposition « le candidat a réussi au rattrapage ».
Avec ça, le 1 désigne l’admission à l’examen, et s’obtient ainsi :

La partie basse de l’arbre signifie que seuls les étudiants assidus ont droit au rattrapage, ce qui en dit long sur la situation actuelle des études supérieures...
De l’arbre au script
Le même arbre peut s’obtenir avec les blocs de Blockly [5] ressemblant à des arbres binaires orientés de gauche à droite : « si ... alors ... sinon ... » :

En Python cela donne quelque chose comme
def admis:
if e:
return True
else:
if a:
if r:
return True
else:
return False
else:
return FalseOn peut d’ailleurs simplifier ce code :
def admis:
if e:
return True
else:
if a:
return r
else:
return FalseLa simplification d’expressions de ce genre est d’ailleurs centrale (!) dans ce sujet.
De l’arbre au graphe
L’exemple donné dans l’énoncé comprend de la redondance :

Par exemple, la proposition c intervient 4 fois, et chaque fois de la même manière. On décide alors de ne la faire intervenir qu’une seule fois, quitte à renoncer au caractère arborescent du graphe :
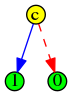
On remarque que même avec ce graphe simplifié, il subsiste encore de la redondance, cette fois avec la proposition b qui intervient deux fois, et chaque fois de la même manière. Cela permet encore une simplification :

L’énoncé s’arrête là mais il est possible de simplifier encore :
Simplification
Le sujet décrit deux modifications de graphe qui peuvent aboutir à une simplification du graphe de décision :
Élimination
L’élimination consiste à remplacer
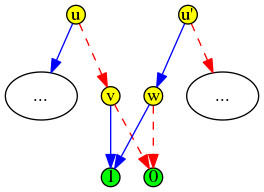
par
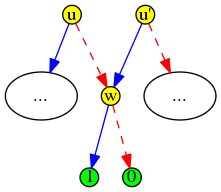
Isomorphisme
L’isomorphisme consiste à remplacer

par
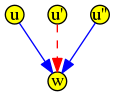
Montrer que l’algorithme converge, ou le programmer en Python, risque d’être plus de niveau post-bac que de niveau terminale. On va donc se concentrer ci-après sur les arbres de décision et leur construction.
On verra dans l’onglet suivant que les arbres syntaxiques sont intéressants parce que les opérations sont, en général, binaires (à deux opérandes). C’est le cas de and et or notamment. Ces opérations booléennes étant à deux opérandes, on s’attend assez logiquement à voir des arbres binaires en logique. Mais la surprise est que le seul opérateur booléen ternaire (à trois opérandes), est à l’origine de ces arbres binaires ! En fait si chaque nœud a deux enfants, il a également un parent [6].
L’opérateur ternaire
En fait, en logique booléenne, on n’utilise guère qu’un opérateur ternaire, et on l’appelle l’opérateur ternaire ou, en anglais, if then else, ci-dessous abrégé en IFT.
Définition de IFT
L’énoncé définit IFT(t,e1,e2) comme étant l’expression
(t and e1) or (not t and e2)
C’est la définition connue par Sympy. En entrant
print(ITE(t,e1,e2))on obtient
Or(And(Not(t), e2), And(e1, t))que Sympy dessine ainsi :

Remarque : L’expression suivante aussi donne l’opérateur ternaire, d’une manière qui permet peut-être de mieux voir l’arbre de décision :

« If t then e1 else e2 » peut se dessiner par cet arbre (qui est un arbre de décision) :
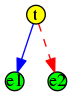
ou par l’expression Python
e1 if t else e2
La puissance de cet opérateur ternaire vient de ce qu’il est possible de s’en servir pour définir les autres opérateurs booléens.
Comment ?
Avec Sympy, en entrant
print(ITE(x,False,True))
print(ITE(x,True,y))
print(ITE(x,y,False))on obtient
Not(x)
Or(And(Not(x), y), x)
And(x, y)On sait donc comment implémenter la négation et la conjonction avec l’opérateur ternaire. Mais pour la disjonction il reste un travail à faire. On obtient à la place, cette expression :

Ceci dit, en entrant
ou = ITE(x,True,y)
print(simplify_logic(ou))on obtient
Or(x,y)
ce qui montre que la solution proposée est bien la bonne.
Voici comment on peut représenter sous forme d’arbres de décision, les opérations booléennes élémentaires :
| non x | x ou y | x et y |

|
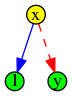
|

|
Il est donc possible de convertir n’importe quelle expression booléenne en arbre de décision (donc, avec les simplifications vues ci-dessus, en graphe de décision).
récursivité
En posant la question à Sympy :
a,b,c,d,e = symbols('a,b,c,d,e')
print(simplify_logic(ITE(ITE(a,b,c),d,e)))
print(simplify_logic(ITE(a,ITE(b,d,e),ITE(c,d,e))))on obtient deux fois la même réponse :
Or(And(Not(a), Not(c), e), And(Not(a), c, d), And(Not(b), a, e), And(a, b, d))
Or(And(Not(a), Not(c), e), And(Not(a), c, d), And(Not(b), a, e), And(a, b, d))ce qui prouve que les deux graphes suivants sont équivalents :
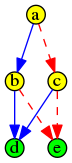
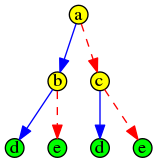
Le passage de l’un à l’autre permet de construire récursivement l’arbre de décision, en partant d’une expression booléenne donnée.
Syntaxe
Si on invoque Sympy avec
from sympy import *
from sympy.printing.dot import *
from sympy.abc import *alors on peut représenter sous forme d’arbres (syntaxiques) les expressions (a+b)² et a²+2ab+b² :
dotprint((a+b)**2)
donne cet arbre
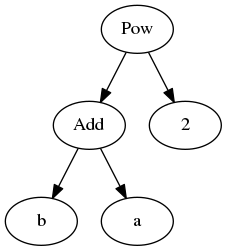
et
dotprint(expand((a+b)**2))
donne celui-là :
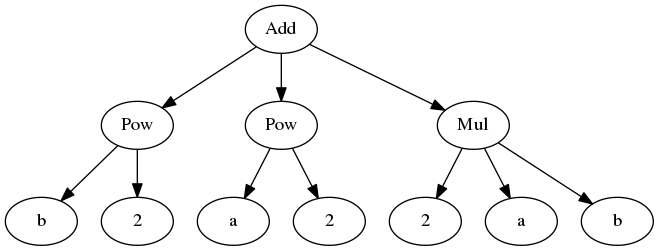
On voit que le premier arbre est celui d’un produit, et le second, celui d’une somme.
Pour aller plus loin, voir
- ces arbres syntaxiques dessinés avec Scratch et CaRMetal,
- cet exerciciel de niveau collège sur les arbres syntaxiques]
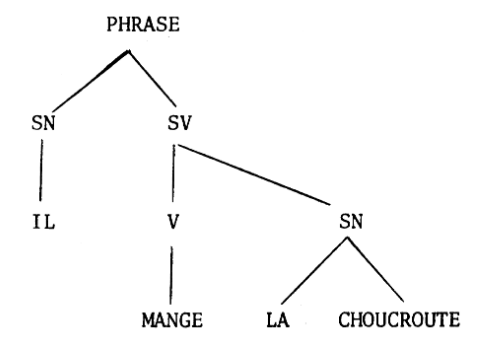
- Le dessin de phrases sous formes d’arbres, par Spacy, vu à la fin de cet article.
Cet arbre a été dessiné par Alain Colmerauer lors de la conception du langage Prolog, basé sur la représentation de phrases en français, par des arbres :
Arbres binaires
Voici un sujet « type bac imaginé faute de sujet zéro » donné en terminale, dont la première moité portait sur les arbres binaires :
Tables de routage
La seconde partie du devoir, hors sujet dans cet article sur les arbres, portait sur les tables de routage. Elle avait été préparée par une activité basée sur celle-ci.
Construire les tables de routage à partir du graphe qui en en bas de la page 6 de ce document a été donné en devoir maison. Mais auparavant, les tables de routages des pages 3 et 4 du même document ont été données, et les élèves ont dû reconstituer le réseau à partir de ces données disponibles.
Bien que disposant de 📜, de ✏️ et d’une gomme, un élève a préféré utiliser l’🖥️ avec le logiciel GIMP :

Cela lui a donné un « brouillon de graphes » :
ensuite reproduit sur papier :

Un autre a préféré (merci à lui) dessiner les étapes de sa recherche sur la feuille :
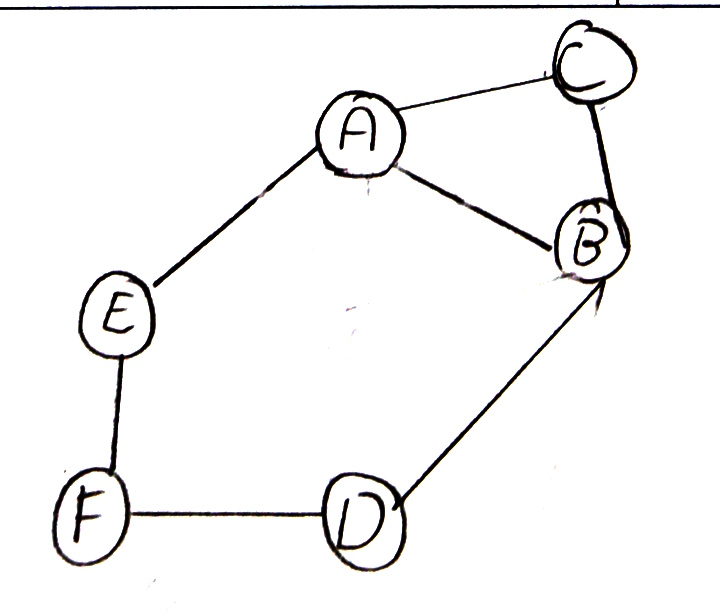
Certains rendus sont justes mais complexes :
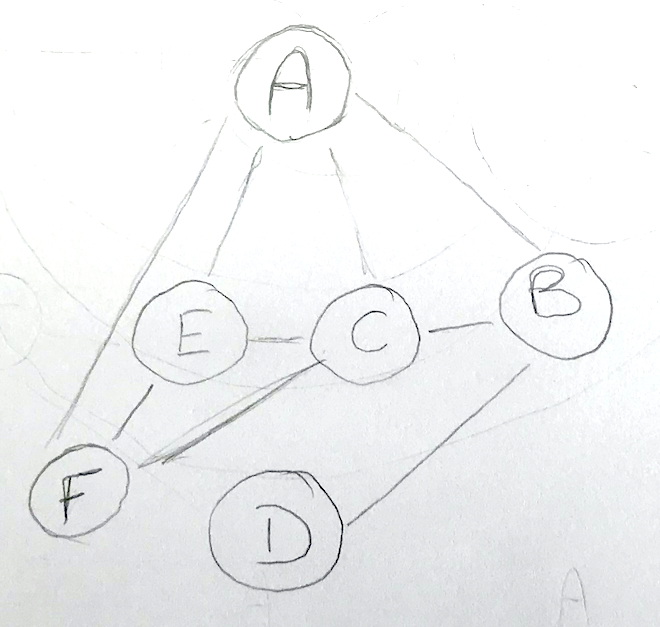
Un élève a choisi arts plastiques en plus de NSI :

Un graphe plus typique :
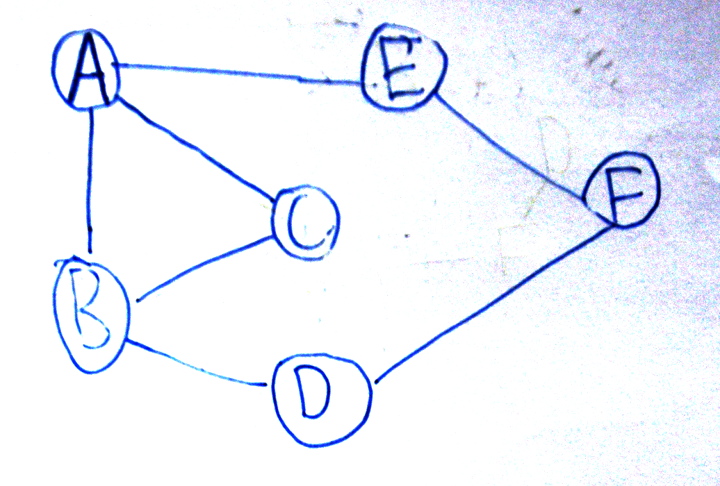
une variante :
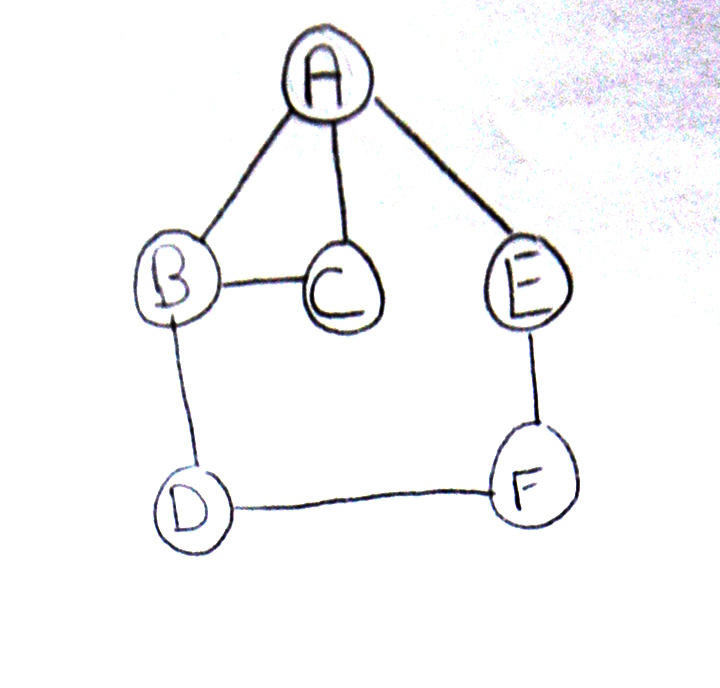
Et voici les rendus de deux élèves rapides, avec optimisation de la forme du graphe :
Et voici un sujet sur les arbres binaires de recherche :
En fait, l’arbre de Stern-Brocot peut être vu comme un arbre binaire de recherche de fractions.
D’autres arbres sont visibles dans cet article (onglet plantes). La tortue de Sofus aussi aime les arbres :

Sujet 0
La numérotation de Jérôme de Sosa permet de stocker tout un arbre binaire dans un tableau. Dans un tel cas, la recherche d’un élément dans un arbre binaire de recherche ainsi codé, revient à une recherche dichotomique dans le tableau (trié). Mais l’énoncé de l’exercice 3 omettant l’adjectif « dichotomique », toute recherche devrait être valorisable, y compris celle-ci, inspirée par le devoir d’un élève :
def recherche(arbre,element):
return element in arbreVoici le sujet :
Pour la démonstration de la question 2, la première partie (prouver que h≤n) est considérée comme évidente : la hauteur maximum pour un arbre binaire est atteinte pour un arbre unaire et vaut alors le nombre de nœuds.
Pour la seconde partie (prouver que n≤2h-1) ça a été plus divers :
- preuve par récurrence
- utilisation de la formule pour la somme des termes d’une suite géométrique
- utilisation de la question 2.3 :
Ajouter une unité à la hauteur à l’arbre revient au maximum à doubler son nombre de sommets, ce qui correspond à un maximum de 2h sommets. Mais comme la racine est seule sur sa hauteur, on peut enlever 1 nœud au résultat.
Pour la question 3, beaucoup d’élèves trouvent la fonction
def indice_du_père(i):
if i%2==0:
return i//2
else:
return (i+1)//2Mais peu d’entre eux pensent à utiliser directement i//2.
Voici des solutions proposées par les élèves pour la dernière question :
Comme arbre[0] n’est pas utilisé dans la numérotation de Sosa (on peut y mettre None par exemple), certains élèves ont choisi d’y stocker la longueur du tableau :
def rechercher(arbre,element):
nb_noeuds = arbre[0]
n = 1
while n <= nb_noeuds:
if arbre[n]==element:
return True
if arbre[n]<element:
n = 2*n+1
else:
n = 2*n
return FalseComme l’arbre est stocké dans un tableau, il suffit de chercher si l’élément est dans le tableau :
def recherche(arbre,element):
if element in arbre:
return True
else:
return FalseRemarque : aucun élève n’a opté pour la solution récursive :
def rechercher(arbre,element,i):
if i>len(arbre):
return False
else:
if element==arbre[i]:
return True
else:
if element<arbre[i]:
return rechercher(arbre,element,2*i)
else:
return rechercher(arbre,element,2*i+1)Clément Lagier, de terminale NSI au lycée Roland-Garros, propose ce corrigé du sujet zéro (hormis l’exercice 2) :
Concours 2021
Le sujet Centrale MP proposait une application des arbres couvrants à des problèmes de pavages :
Le sujet X-ENS quant à lui, évoquait les arbres de mots :
Les arbres pondérés sont évoqués à la fin de cet article.

Commentaires