Une légende dit que c’est alité par une maladie, que Descartes aurait eu l’idée d’associer les points du plan à des couples de nombres. Voici ce qu’en écrit Cauchy, en 1823 :

La notion de couple, même avant d’être formalisée, est donc omniprésente en mathématiques, notamment en géométrie repérée et en analyse, faisant intervenir des couples (x,y). Un graphe orienté est un ensemble de couples (inclus dans le produit cartésien) donc cette notion est fondamentale, puisque les relations (en particulier les fonctions) sont des graphes orientés.
Emballer pour accoupler
La théorie des ensembles consiste à regrouper des objets (les éléments) dans des collections (les ensembles d’objets). Par exemple si on veut regrouper les éléments a et b :

on peut mettre une enveloppe (« patatoïde ») autour des 2 éléments :

Mais la paire obtenue n’est pas un couple, puisque d’une part on ne peut distinguer les rôles de a et b, d’autre part si a = b, on n’obtiendra qu’un singleton alors qu’un couple doit vraiment avoir deux élements (le premier élément, et le deuxième élément).
Envelopper séparément a et b ne résout pas le problème :
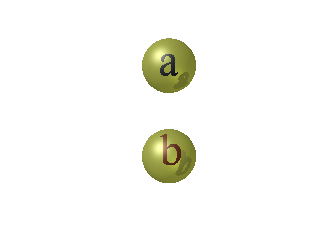
En effet cela produit 2 singletons (ensembles à un seul élément chacun, et si a = b on n’aura qu’un seul singleton, avec de surcroît l’absence d’ordre entre les singletons.
Voici une autre manière d’emballer qui permet un vrai accouplement et pas seulement un appariement :
Voici comment le couple (a,b) est modélisé dans la théorie des ensembles de Tarski et Grothendieck :
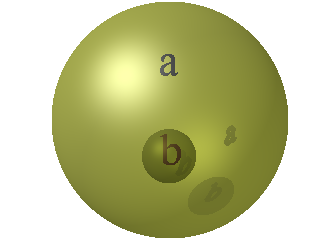
Ceci est bien un couple
Tout d’abord, les couples (a,b) et (b,a) sont bel et bien différents l’un de l’autre :
| (a,b) | (b,a) |
|
|
|
Ensuite, le couple (a,a) peut être modélisé par cette technique :

Les entiers naturels entièrement emballés
Chez Alfred North Whitehead et Bertrand Russel, la théorie des ensembles permet de construire les entiers :
L’ensemble vide modélise l’entier 0 :

- En emballant 0 on obtient 1 :

- En emballant 0 et 1 on obtient 2 :

- En emballant 0, 1 et 2 on obtient 3 :

La construction des entiers naturels par des ensembles remonte à Von Neumann.
La construction des entiers naturels par Von Neumann n’est pas si naturelle que ça (celle des numéraux de Church non plus). La modélisation des couples en théorie des ensembles souffre du même problème, et il semble préférable de considérer la notion de couple comme une notion primitive. La notion est abordable intuitivement dès le milieu de cycle 2, en notant a→b le couple (a,b). C’est la notation avec les parenthèses qui est moins intuitive.
D’autres modélisations ont été proposées depuis plus d’un siècle.
Histoire de couples
Cantor et Frege proposaient de modéliser le couple (a,b) comme ensemble des relations R telles que aRb. Cette définition est circulaire car une relation est un ensemble de couples.
En 1914, Felix Hausdorff propose cette modélisation du couple (a,b) :
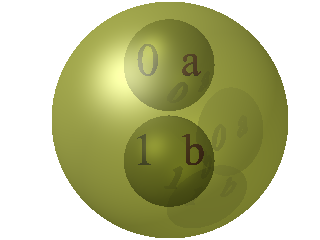
La ressemblance avec l’idée initiale de Kuratowski (voir la partie sur l’algèbre de Boole) cache le fait que cette définition ne fonctionne pas si a=0 ou b=1.
À la même époque, Norbert Wiener propose cette autre modélisation :

L’idée est de séparer a et b par des emballages différents. Cette définition est correcte, mais on a vu ci-dessus qu’il y a plus simple (moins de papier d’emballage nécessaire).
En 1921, Casimir Kuratowski s’intéresse, comme on l’a déjà vu dans la partie sur l’algèbre de Boole, à l’idée de définir un couple comme un ensemble muni d’une relation d’ordre :

On constate que Kuratowski utilise l’expression paire ordonnée plutôt que le mot couple et la notation des parenthèses pour désigner les ensembles et pas les n-uplets. Voici son modèle pour le couple (a,b) :
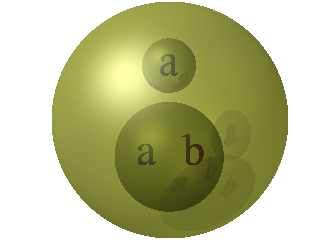
Il est très proche du modèle de Tarski-Grothendieck, à part que a est suremballé. Ce souci constant de mettre les éléments a et b au même niveau est dû à la crainte (chez Wiener comme chez Kuratowski) du paradoxe de Russel.
Pourquoi Kuratowski a-t-il abandonné la définition un couple est un ensemble ordonné au profit de cette construction ? Parce que là encore, la définition est circulaire, la relation d’ordre étant une relation, donc un ensemble de couples.
En 1931, Kurt Gödel écrit ceci dans son célèbre article [2] :

Cela correspond à ce modèle, intermédiaire entre celui de Kuratowski et celui de Tarski-Grothendieck :

Gödel propose aussi cette variante :

On remarque que Gödel parle de geordnete Paare comme Kuratowski, et note lui aussi les ensembles entre parenthèses. Il a besoin de parler de relations (pour la logique des prédicats) et définit une relation (ou un prédicat) comme un ensemble de couples. C’est à cette occasion qu’il construit un couple comme un ensemble d’ensembles.
C’est chez Bourbaki que la modélisation vue ci-avant semble être apparue pour la première fois.
La lambada se danse en couple, le lambda-calcul parfois aussi
Dans la mathématique bourbakiste, on a donc cette construction :
- Une fonction est un ensemble de couples.
- Un couple est un ensemble (dont l’un des éléments est lui-même une paire ou un singleton).
- La notion d’ensemble est primitive et tout le reste est basé dessus.
Pour Alonzo Church, la situation est plutôt inverse :
- La notion de fonction est primitive (« tout est fonction »).
- L’encodage de Church permet alors de construire les couples à partir des fonctions, dans le λ-calcul.
- Les couples sont tellement omniprésents qu’il est possible de modéliser les listes par les couples.
- Munie d’une fonction de hachage, une liste peut alors modéliser un ensemble.
On verra plus bas comment les couples permettent de modéliser des listes. Pour la construction du couple (a,b) en λ-calcul, c’est plutôt simple : on applique la fonction a à la fonction b. Le λ-calcul de Church étant non typé, il est en effet possible d’appliquer une fonction à elle-même (modélisation du couple (a,a) en appliquant la fonction a à elle-même). Et le résultat de l’application de a à b n’est pas nécessairement le même qu’en appliquant la fonction b à a.
Cependant on préfère appliquer une fonction aux deux arguments a et b : le couple (a,b) est donc modélisé par la fonction qui, à toute fonction z, associe z(a,b) :

Pour utiliser les couples, il faut trois choses :
- une projection sur le premier élément (notée par des crochets couple[0] en Python) nommée first ci-après ;
- une projection second sur le second élément (notée couple[1] en Python) ;
- un constructeur de couple, noté cons ci-après.
La première projection est visible dans la moitié gauche de cette image (la moitié droite est le couple (a,b) comme on l’a vu ci-dessus :
Voici les étapes du λ-calcul (réductions successives) mené sur first (a,b) :



On retrouve bien a comme réduction finale : le premier élément du couple (a,b) est bien a.
Quant à la seconde projection, elle donne, appliquée au couple (a,b), la valeur finale b, comme on le voit sur les étapes de cette réduction (seconde projection dans la moitié gauche, couple (a,b) dans la moitié droite) :



Enfin, comme on a vu plus haut comment le couple (a,b) est représenté en λ-calcul, la fonction cons de construction d’un couple est simplement la fonction qui, à xet y, associe le couple (x,y) :


Une variable est un couple
Dans cet article de l’Encyclopédie, d’Alembert écrit que
on appelle quantités variables en Géométrie, les quantités qui varient suivant une loi quelconque. Telles sont les abscisses & les ordonnées des courbes, leurs rayons osculateurs, &c.
On les appelle ainsi par opposition aux quantités constantes, qui sont celles qui ne changent point, comme le diametre d’un cercle, le parametre d’une parabole, &c.
On exprime communément les variables par les dernieres lettres de l’alphabet x, y, z.
Pour les encyclopédistes, une variable possède donc un nom (pour l’« exprimer ») et une quantité.
Un modèle de mémoire informatique a été proposé en 1977 par Dana Scott, comme fonction qui, à un emplacement mémoire, associe son contenu :

Ainsi, à un lieu L, on associe une valeur V. Ce que Scott nomme lieu correspond au nom de la variable [6].
Comme une fonction est un ensemble de couples, une variable est donc un couple :
- Son premier élément est le nom de la variable (de type str c’est-à-dire élément d’un langage).
- Son second élément est la valeur de la variable (souvent un nombre, mais pas nécessairement).
Voici une petite expérience en Python, pour prouver qu’une variable est effectivement un couple : sur une calculatrice, il y a un bouton var permettant de voir les variables. En Python, c’est la fonction globals qui permet de connaître les variables.
Au début on a quelque chose comme
>>> globals()
{'__package__': None, '__name__': '__main__', '__spec__': None, '__doc__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__builtins__': <module 'builtins' (built-in)>}Ensuite on crée une variable v par affectation :
v = 3
Et v est apparu dans le dictionnaire des variables :
>>> globals()
{'__package__': None, '__name__': '__main__', 'v': 3, '__spec__': None, '__doc__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__builtins__': <module 'builtins' (built-in)>}On voit que la variable v est apparue et que son premier élément est bien entre guillemets : c’est un nom. Les couples sont peut-être peu reconnaissables dans cette écriture d’un dictionnaire Python, mais ils sont bel et bien stockés sous le nom d’« items » :
>>> globals().items()
dict_items([('__package__', None), ('__name__', '__main__'), ('v', 3), ('__spec__', None), ('__doc__', None), ('__loader__', <class '_frozen_importlib.BuiltinImporter'>), ('__builtins__', <module 'builtins' (built-in)>)])La variable v qu’on a créée ci-dessus apparaît sous cette forme :
('v', 3)
ce qui confirme que Python est conforme au modèle de Scott et Strachey.
Emballages
Il n’y a pas que pour construire un couple en théorie des ensembles, que l’idée d’emballer dans plusieurs couches un (ou plusieurs) objet mathématique, s’est révélée fructueuse. On va voir ici, comme un bonus à cet article, trois exemples d’utilisation en informatique :
- Les monades en Haskell
- Les décorations de fonctions en Python.
- Le sucre syntaxique des langages de programmation
monades
Un exemple archétypal de foncteur est la fonction map de Python. Par exemple, à partir de la catégorie des réels, map transforme une fonction R→R en une fonction (N→R)→(N→R) (à une liste L1 de réels, elle associe une liste de réels). Ce genre de foncteur, en Haskell, s’appelle une monade :
Une monade est un foncteur M assorti de deux fonctions
- unit (ou return) de type a → M a
- join de type M M a → M a
En, bref, la monade M permet d’emballer a dans un paquet cadeau M a, sans qu’il y ait besoin de suremballer, puisqu’une deuxième couche peut être réduite (par join) à une seule.
La construction des ensembles peut être faite en programmation fonctionnelle, par cette monade :
| à ces deux objets a et b | unit associe ces deux ensembles |
|
|
|
Dans ce cas la jointure est la réunion ensembliste (à un ensemble d’ensembles elle associe leur réunion).
Une monade sert donc à emballer ou empaqueter une fonction (en Haskell tous les objets sont des fonctions). On parle d’encapsulation.
Leibniz
Noter que dans sa monadologie, Leibniz évoquait un concept quelque peu opposé à celui des monades de Haskell :

1. La Monade, dont nous parlerons ici, n’est autre chose qu’une substance simple, qui entre dans les composés ; simple, c’est-à-dire sans parties.
Leibniz semble décrire plutôt les éléments qui sont dans l’ensemble, que l’ensemble.
L’idée de déballer le paquet pour aller chercher ce qui est dedans (jointure) est également niée par Leibniz :
7. Il n’y a pas moyen aussi d’expliquer comment une Monade puisse être altérée ou changée dans son intérieur par quelque autre créature, puisqu’on n’y saurait rien transposer, ni concevoir en elle aucun mouvement interne, qui puisse être excité, dirigé, augmenté ou diminué là dedans, comme cela se peut dans les composés, où il y a des changements entre les parties. Les Monades n’ont point de fenêtres, par lesquelles quelque chose y puisse entrer ou sortir. Les accidents ne sauraient se détacher, ni se promener hors des substances, comme faisaient autrefois les espèces sensibles des scolastiques. Ainsi ni substance, ni accident peut entrer de dehors dans une Monade.
On peut se demander à quoi ça sert, en Haskell, d’emballer une fonction dans un paquet cadeau. En fait, les monades sont très utilisées pour gérer les effets de bord chers à Dana Scott, en ajoutant quelque chose (le contexte, des variables globales ou l’environnement) dans le paquet. Les monades les plus importantes sont IO (entrées-sortie) et State (état de la machine). Elles sont similaires au itérateurs de Python, qui à chaque appel, gardent mémoire de l’état de l’itération. Mais en Python, enrober une fonction avec une variable globale, se fait par un décorateur.
décorateurs
En Python, ce sont les fonctions que l’on décore. En fait il ne s’agit pas que d’emballer la fonction dans du papier cadeau, mais plutôt de la transformer (par des ajouts).
Pour voir à quoi cela peut servir de modifier une fonction après l’avoir définie, on va prendre pour exemple un problème qui se pose chaque fois que l’on veut représenter graphiquement une fonction prenant de grandes valeurs. Par exemple l’hyperbole représentant la fonction inverse est difficile à afficher avec matplotlib.pyplot :

Pour pouvoir représenter graphiquement une fonction qui n’est pas définie en 0, on s’arrange pour remplacer 0 par une valeur proche mais possédant un inverse. La fonction représentée graphiquement est donc définie ainsi :
def inverse(x):
if x==0:
x = 1e-6
return 1/xComme on a approché 0 par 10-6, la première ordonnée est 1000000 et on ne voit pas bien l’hyperbole. Pour résoudre ce problème, on propose de limiter les ordonnées (par exemple en leur imposant d’être comprises entre -1 et 1). La fonction faisant cela est une fonctionnelle (fonction dont la valeur d’entrée et la valeur renvoyée sont elles-mêmes des fonctions), que voici :
def limiter(f):
def fL(x):
if -1<=f(x)<=1:
return f(x)
elif f(x)<-1:
return -1
else:
return 1
return fLLa valeur d’entrée f est donc la fonction à limiter, pour ce faire on définit une fonction fL (fonction limitée) dépendant de la variable x∈R et qui coïncide avec f(x) si x est entre -1 et 1, avec -1 ou 1 sinon. La fonctionnelle limiter modifie la fonction f selon cet algorithme :
- elle définit une fonction locale fL, qui est la version limitée de f (les valeurs renvoyées sont entre -1 et 1) ;
- elle renvoie cette fonction ;
- pour en faire un décorateur, il reste à remplacer la fonction non limitée, par la fonction limitée.
Pour mieux voir l’hyperbole, il suffit maintenant de précéder la définition de la fonction inverse, d’un appel à la limiter :
@limiter
def inverse(x):
if x==0:
x = 1e-6
return 1/xCette seule ligne ajoutée avant la définition de la fonction donne une hyperbole bien mieux visible :

On peut se demander à quoi cela sert de décorer une fonction, plutôt que de la modifier directement. L’intérêt essentiel des décorateurs est qu’ils peuvent servir plusieurs fois.
sucre
Le sucre syntaxique s’applique à un langage de programmation. L’expression s’inspire du fondant (pâtisserie) :
- D’une part on enrobe le langage (on lui rajoute des choses sans rien lui enlever).
- D’autre part le résultat a un goût agréable (sucré) : le nouveau langage (enrichi) est plus naturel.
Par exemple CoffeeScript est décrit comme du sucre syntaxique sur JavaScript. Ce qui signifie que pour obtenir la fonction Javascript suivante :
var sinus;
sinus = function(x) {
return sin(x / pi * 180);
};on entre simplement ceci dans l’interpréteur CoffeeScript :
sinus = (x) -> sin x/pi*180
C’est plus court et plus proche de la langue naturelle. Ce que l’on résume par l’expression sucre syntaxique.
Histoire de parenthèses
Toujours en CoffeeScript, si on écrit simplement
sin x
l’équivalent JavaScript obtenu est
sin(x);
Au début du 18e siècle, l’image de x par f était notée fx. Le premier à utiliser des parenthèses pour englober l’argument et noter f(x) à la place, est Leonhard Euler, dans cet article de 1734 sur le calcul infinitésimal (longueurs de courbes) :

Dans la seconde phrase, il écrit que f(x/a+c) est l’image de x/a+c par la fonction f. La notation s’est très largement généralisée jusqu’à aujourd’hui, au point que les parenthèses sont considérées, en Python, comme une opération de passage des arguments à la fonction.
Pourtant une autre notation que f(x) existe depuis longtemps, c’est f x. Par exemple
- on écrit aussi souvent sin x que sin(x) ;
- on écrit aussi souvent cos x que cos(x) ;
- on écrit plus souvent ln x que ln(x).
La notation utilisée dans CoffeeScript a donc du sens, elle est également présente dans les langages de programmation fonctionnelle comme Haskell, dans Ruby, et comme on l’a vu dans CoffeeScript : dans ces langages, les parenthèses sont optionnelles. Le sucre c’est l’absence (facultative) de parenthèses, la syntaxe c’est les parenthèses que l’on peut (et parfois, doit) mettre quand même. Les règles du λ-calcul expliquent quand on peut se passer de parenthèses, et lorsqu’on en a la possibilité, on le fait pour éviter d’être submergé.
Syntaxe et grammaire
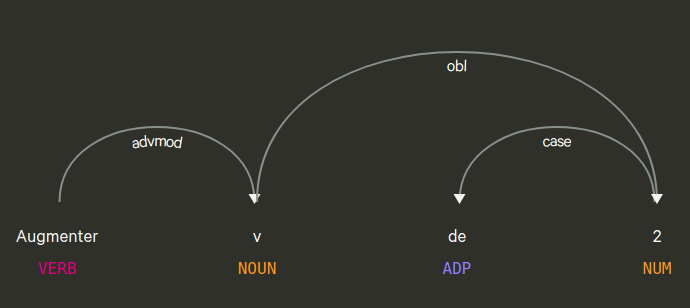
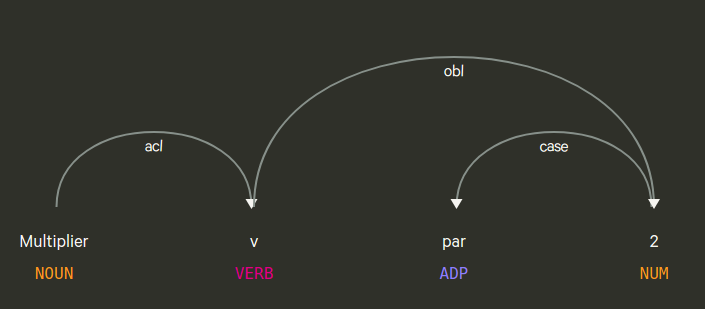
La phrase « Augmente v de 2 » (écrite à l’impératif pour montrer que c’est une phrase) ne comporte pas de sujet : celui-ci est implicite car à l’impératif, le sujet est toujours l’interlocuteur à qui on donne un ordre. Il reste alors 3 éléments à analyser grammaticalement dans cette phrase :
- « augmente » est le verbe de cette phrase, il indique une action à effectuer ;
- « v » est le complément d’objet direct, il indique sur quoi doit porter l’action (qu’est-ce qu’il faut augmenter) ;
- « de 2 » est le complément d’objet indirect, il indique comment augmenter v ; il est formé de deux mots :
- « de » est une préposition (c’est à cela en général, qu’on reconnaît un complément indirect), il indique le rapport entre ce qui précède et ce qui suit :
- « 2 » est un nom indiquant la quantité dont il faut augmenter v.
Spacy confirme cette structure de la phrase, par ce graphe :
On a vu dans la partie sur bash, que cette même phrase (sans la majuscule au début) est correctement comprise et interprétée par bash :
♟️ echo $v
3
♟️ augmenter v de 2
♟️ echo $v
5Quel miracle permet à bash de « comprendre » aussi bien la langue française ? Vous l’avez deviné, c’est le sucre syntaxique. Pour rappel voici la fonction écrite en bash :
function augmenter {
let "$1=$1+$3"
}Elle fait que le premier argument (supposé être une variable) est affecté par la somme de sa valeur actuelle, et de celle du troisième argument. Le second argument n’est donc pas utilisé. Les commandes suivantes auraient eu le même effet :
augmenter v par 2
augmenter v pour 2
augmenter v plus 2
augmenter v dans 2
augmenter v de 2
augmenter v augmentant 2
augmenter v autour 2
augmenter v vautour 2
augmenter v maison 2
augmenter v camion 2
augmenter v 2 2
augmenter v 42 2
augmenter v sur 2
augmenter v v 2alors qu’elles n’ont pas vraiment de sens.
L’affectation fonctionne de la même manière :
function mettre {
let "$3=$1"
}Le second argument n’est pas utilisé, il n’est donc pas nécessaire qu’il soit « dans ». Voici la structure grammaticale de la phrase « mettre 3 dans v » :
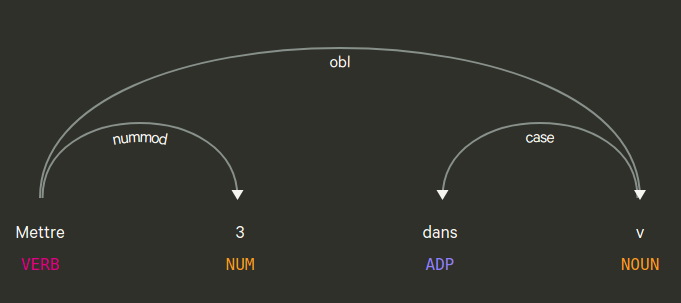
Note : cette manière d’écrire l’affectation d’une variable remonte au tout début des langages informatiques évolués, puisqu’elle est dûe à Grace Hopper qui est l’auteur du premier compilateur. Cette fois-ci, le nombre 3 est complément d’objet direct, et la variable v est dans le complément d’objet indirect « dans v ». Depuis Fortran, l’usage est aujourd’hui de noter l’affectation comme une relation infixe (= ou := ou ←) et de mettre le nom de la variable à gauche, ce qui en fait le sujet de la phrase. « v←3 » se traduit alors par la forme passive de la phrase précédente, comme « v prend 3 » ou « v accepte 3 » ou « v est affecté par 3 ». Ce qui est moins proche de la langue usuelle, que la forme active « mettre 3 dans v ». C’était du moins l’opinion de Grace Hopper.
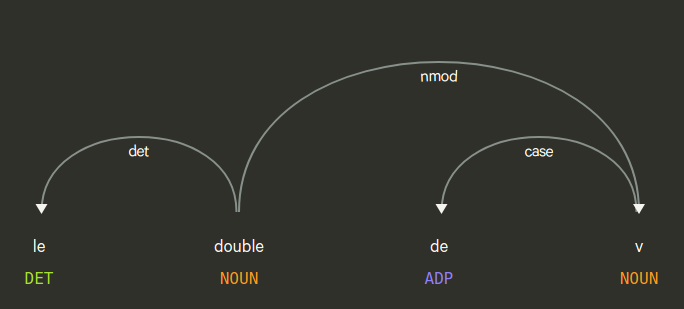
La modification en place des variables de Sofus permet également d’écrire des phrases sans complément d’objet indirect, comme celle-ci qui n’a que le complément d’objet direct :

Noter que le graphe syntaxique permet de voir la différence entre « doubler » et « le double » puisque cette expression n’est même pas une phrase complète (il n’y a pas de verbe) :
Commentaires