
Les experts du m’raha wa n’tso à Mayotte ne comptent jamais les graines (Tiennot communication privée). Pour le katro de Madagascar, seuls les enfants ont le droit de compter les graines, sinon le seul fait d’avoir touché ne serait-ce qu’une graine, oblige à semer depuis la case où se trouvait cette graine. Toujours à Madagascar (Tiennot communication privée) les marchands de fruits connaissent avec une grande précision le cardinal d’un tas de fruits sans compter ceux-ci. Quand à Mayotte, les champions du m’raha wa n’tso savent avec précision (cette connaissance étant d’importance stratégique) le nombre de graines contenu dans la nyumba (la case de forme carrée) sans jamais compter ces graines.

Comment font-ils ? Une première possibilité est qu’ils aient mémorisé les nombres de graines au cours de la partie (ou alors qu’ils aient compté les coups joués, et les graines des cases peu remplies, et retrouvé le cardinal des nyumbas par déduction), ce qui suppose une mémoire de travail impressionnante. Une seconde est qu’ils savent estimer avec précision un grand nombre entier.
Dans cet article, on se propose d’explorer la manière dont des machines (vous avez dit IA ?) peuvent dénombrer sans compter. On peut dénombrer par pesée, par estimation du volume, voire par le regard.
Premier projet : dénombrement par pesage
Un plateau de jeu de semailles (par exemple, Sowing à 6 cases) pédagogique est un alignement de cases (où on sème des graines), chacune d’entre elles ayant en son fond une jauge de contrainte, permettant de mesurer la masse du tas de graines ; de plus, à côté de chaque case, figure un afficheur LED indiquant le nombre de graines actuellement dans la case. Quelque chose comme
{kind=link}
{kind=link}
qui peut aider les jeunes élèves à apprendre à associer les chiffres et les nombres. Voici un exemple de ce qui est attendu :

Un problème qui se pose avec la pesée de graines, est que celles-ci ne sont pas calibrées avec précision. Une mesure effectuée sur les 48 graines d’un jeu de katro indique une masse moyenne de 2,583g et un écart-type (estimé) de 0,414g. Le tracé d’une droite de Henry :
suggère, avec un coefficient de corrélation de carré 0,988 que la modélisation de la masse d’une graine par une variable aléatoire normale de paramètres 2,583g et 0,414g est pertinente dans ce contexte. En supposant qu’il y a indépendance entre les masses des graines, la masse du tas de graines est alors normale de paramètres et et le quotient de cette masse totale par 2,583 suit lui aussi une loi normale, de paramètres et . La probabilité qu’elle soit comprise entre et (c’est-à-dire que son arrondi entier soit correct) est donnée dans le tableau suivant :
| 1 | 0,998221949401783 |
| 2 | 0,972874613820933 |
| 3 | 0,928803110724748 |
| 4 | 0,881829754134665 |
| 5 | 0,837749500152768 |
| 6 | 0,797965253549604 |
| 7 | 0,762452482209559 |
| 8 | 0,730777292410847 |
| 9 | 0,702433751636496 |
| 10 | 0,676951054399075 |
| 11 | 0,653921494553211 |
| 12 | 0,633001454164905 |
On voit que, pour des grands tas (ceux-là même où l’humain est peu performant pour ce qui est de dénombrer), la probabilité de se tromper est d’une chance sur trois, ce qui n’est pas négligeable.
Pour réaliser ce projet, par exemple sur un Sowing pédagogique à 6 cases, il faut
- un microcontrôleur type Arduino ou ESP-32,
- 6 capteurs de type jauge de contrainte, dont les signaux sont multiplexés pour pouvoir n’utiliser qu’un seul convertisseur analogique-numérique du ESP-32 (lequel dispose de 8 canaux tout de même),
- 6 actuateurs de type affichage LED 7 segments, un (deux s’il risque d’y avoir plus de 9 graines) par case, avec interfaces séries permettant de les programmer en binaire, et chacun branché sur une sortie numérique du ESP-32.
Le module ESP-32 peut être programmé en micropython. Le plateau serait plus pédagogique si les chiffres étaient affichés en calligraphie : ce sont les formes que les enfants doivent apprendre à reconnaître.
Variante avec machine learning
L’initiation au machine learning commence souvent par la régression linéaire (qui est un apprentissage supervisé pour une prédiction) et il se trouve que justement le tableur permet de calculer une droite de régression, et qu’en plus les fonctions affines sont au programme de mathématiques de Seconde.
Le matériel nécessaire est composé de
- machines ESP-32 (programmables en micropython ; idéalement une par élève),
- jauges de contrainte (à brancher sur une entrée analogique de l’ESP-32),
- ordinateurs, sur chacun desquel est installé Thonny et un tableur.
Ci-dessous, à gauche c’est la carte ESP-32, au centre l’amplificateur hx-711, et à droite la jauge de contrainte avec 10 graines de soja noir posées dessus :

Une fois lancé Thonny et branché (par USB) l’ESP-32, il faut changer l’interpréteur Python pour choisir celui de l’ESP-32, pour cela on va dans exécuter :
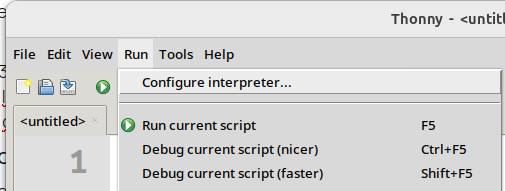
Là, on choisit la version ESP-32 :
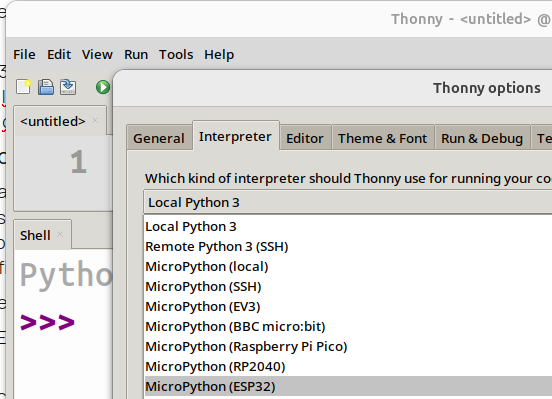
on clique dessus :
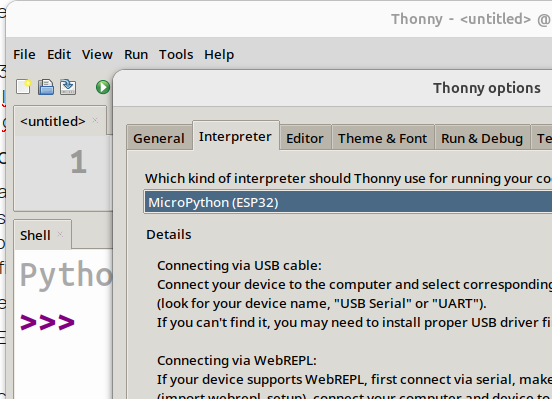
puis sur OK, ce qui a pour effet de redémarrer Python, mais en mode ESP-32 :
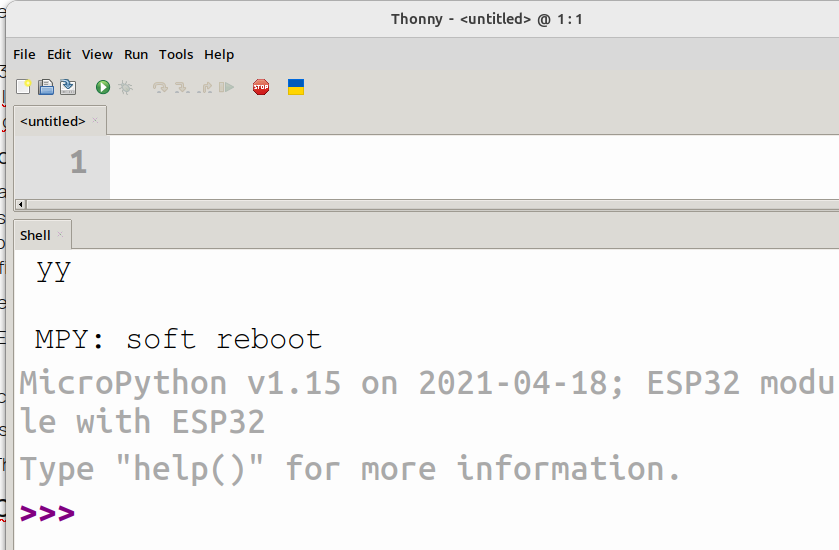
Ensuite, on déclare un objet de type broche, avec Pin (importé du module machine), comme entrée analogique, Puis on commence l’apprentissage, dont chaque étape consiste à
- choisir un entier ,
- poser graines sur le plateau,
- lire (avec la méthode read de la broche) la masse du tas de graines,
- entrer dans la colonne A le résultat de la lecture,
- entrer dans la colonne B le nombre .
En recommençant sur plusieurs lignes du tableur des données de ce genre, on réalise l’apprentissage. Il est conseillé de choisir au moins une fois chaque valeur de entre 0 et 12 (compris). La phase suivante consiste à dessiner le nuage de points, puis tracer la doite de régression, avec son équation.
L’utilisation consiste à mettre des graines sur le plateau, lire la tension aux bornes du plateau, puis calculer son image par la fonction affine construite dans l’apprentissage, et arrondir à l’entier le plus proche pour avoir une estimation du nombre de graines. Ensuite on vérifie si l’estimation correspond au nombre réel de graines. En munissant la jauge de contrainte d’un amplificateur hx-711, et à l’aide de la bibliothèque Python permettant de gérer le tout, on peut effectuer des mesures en lançant ce script :
from hx711_gpio import HX711
from machine import Pin
pin_sck = Pin(22, Pin.OUT)
pin_dout = Pin(23, Pin.IN)
hx = HX711(pin_sck, pin_dout, gain=128)Ensuite, dans la console Python, il suffit de
- poser quelques graines sur la balance,
- évaluer dans la console l’expression
hx.get_value(), - noter le résultat dans une cellule du tableur (colonne 1) et le nombre de graines dans la cellule voisine (colonne 2)
Au bout de quelques mesures notées (phase d’apprentissage supervisé), il est possible de dessiner le nuage de points, puis de demander la droite de régression (donnant n fonction de la mesure) :
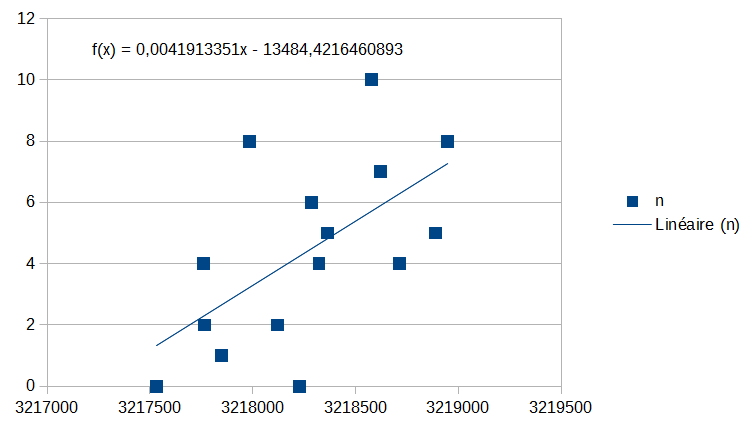
Ensuite on peut utiliser le modèle pour une estimation en programmant la fonction affine en Python :
def f(x):
return round(0.00419133506877983*x-13484.4216461023,0)(on arrondit à zéro chiffre après la virgule parce qu’il y a un nombre entier de graines)
Pour utiliser le modèle, on pose des graines sur la balance puis on évalue dans la console l’expression f(hx.get_value()) pour estimer le nombre de graines. On ne s’attend pas à avoir une estimation correcte à chaque fois, par exemple ci-dessous on a mis trois graines pour en estimer 5 :

Second projet : dénombrement par regard
Avec ImageJ
Usuellement, quand on veut estimer le nombre de manifestants dans une manif ou le nombre de globules rouges dans une goutte de sang, on ne le fait ni par pesée ni par comptage. Une application intéressante sur le smartphone serait celle qui afficherait sur l’écran de la webcam des cadres de ce genre :

Avec le logiciel libre ImageJ, on peut compter ces graines :

Les ombres gênent la visibilité, au point que si on essaye d’analyser cette image sans retouche, ImageJ ne compte que les constellations :
Il faut donc d’abord séparer les graines et les ombres. Comme ici les graines sont rougeâtres, on peut effectuer un filtrage passe-bande :

Le rouge ressort bien par rapport à l’ombre grise, et du coup la composante verte de l’image porte des graines plus foncées que le reste :

Ensuite on choisit un seuil au-delà duquel la couleur est suffisamment foncée pour être une graine :

La suite est de la topologie : on demande à ImageJ de compter les composantes connexes (analyse particles) de la partie noire de l’image. Le résultat (pour les « particules » de 400 pixels² à l’infini) est ici :
| Area | Mean | |
| 1 | 1423 | 246.936 |
| 2 | 1474 | 253.789 |
| 3 | 1154 | 254.337 |
| 4 | 1415 | 250.855 |
| 5 | 1670 | 247.671 |
| 6 | 1209 | 241.079 |
| 7 | 1029 | 248.309 |
| 8 | 1520 | 253.658 |
| 9 | 1450 | 255.000 |
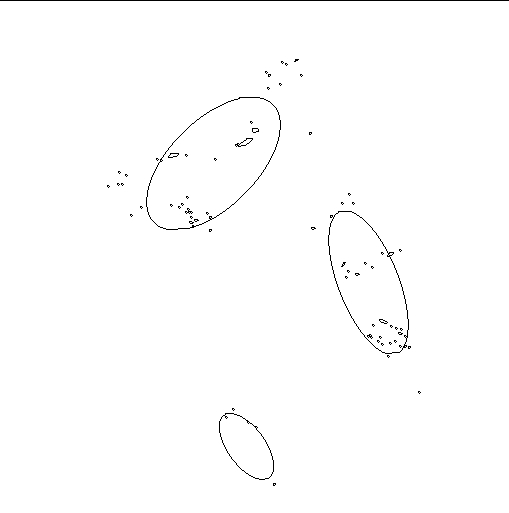
ImageJ compte 9 composantes connexes, donc 9 graines dans l’image. Elles peuvent être numérotées :
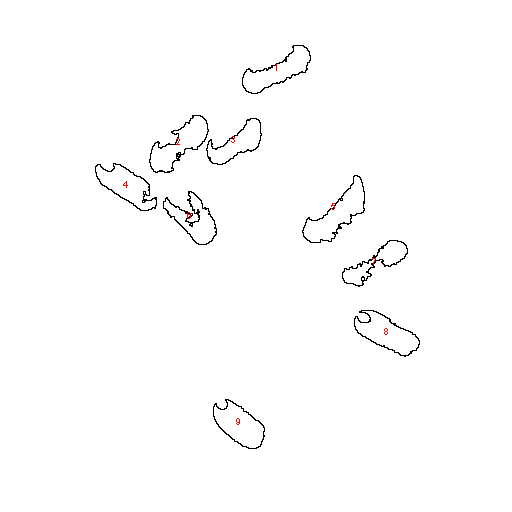
ou schématisées par des ellipses :

Très bien : l’ordinateur sait compter au moins jusqu’à 9. Sauf que la suite d’opérations précédentes n’est pas automatisable (dans un script), notamment parce que le choix du seuil a été fait manuellement, et il n’est pas facile de déléguer ce choix à un algorithme. Par exemple, avec la nyumba qui ouvre cet article, on voit que seules quelques ombres (et aucune graine, celles-ci sont trop claires) ont été comptées :

Ce projet peut néanmoins être tenté en cours de SNT (thèmes : les objets connectés, et la photographie numérique),
- soit directement avec ImageJ,
- soit avec le module Python openCV,
- soit avec appInventor, du MIT, en programmation par blocs, pour les smartphones Android, ou l’équivalent Apple pour les iPhones.
Avec openCV
Python possède un module opencv permettant de faire du traitement d’images (y compris en vidéo). Avec
import cv2
import numpy as npon dispose d’une fonction cv2.imread qui permet d’importer une image (comme celle de nyumba déjà vue) dans une variable img, puis de la mettre en noir et blanc et lui appliquer une transformée de Hough circulaire avec
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (9,9), 2)
circles = cv2.HoughCircles(
gray,
cv2.HOUGH_GRADIENT,
dp=1.2,
minDist=20,
param1=100,
param2=30,
minRadius=30,
maxRadius=60
)Avec ces paramètres seules 2 graines sur les 12 n’ont pas été détectées :
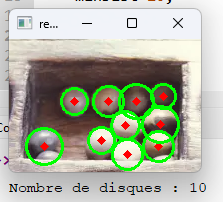
En effet elles sont partiellement cachées par le bord inférieur du plateau et la partie visible n’a pas une forme circulaire. D’ailleurs cet algorithme (dû à Serge Bays) ne fonctionne pas avec des graines de forme allongée.
Avec un réseau de neurones
Les nombreuses caméras chinoises sont dotées de réseaux de neurones qui ont appris à reconnaître des visages. Sauraient-elles reconnaître (et dénombrer) des graines ? Pour simuler un réseau de neurones, on utilise le module keras de Python. Pour un apprentissage supervisé, a été créé un jeu de données artificiel, composé d’images de 256 pixels comportant des images de graines ne se chevauchant pas trop :
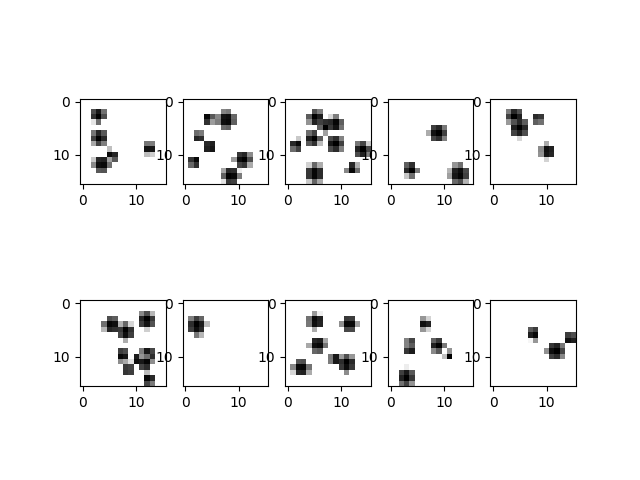
ainsi que le nombre de graines de chaque image (ci-dessus [5, 7, 9, 3, 4, 9, 1, 6, 6, 3]). Après plusieurs essais, ce réseau de neurones a été choisi :
p = 8
modele = Sequential([
Conv2D(p,3,input_shape=(16,16,1)),
MaxPooling2D(pool_size=2),
Flatten(),
Dense(10,activation='softmax')])
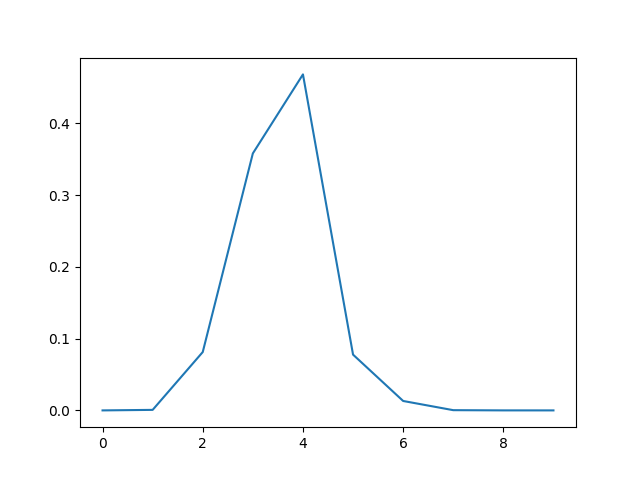
modele.compile(loss='categorical_crossentropy',optimizer='sgd',metrics=['accuracy'])Avec la descente du gradient comme optimiseur, on est déçu par la faible précision 0,5206666588783264 : le réseau prédit correctement le nombre seulement une fois sur deux. Par exemple cette image a été vue comme représentant le nombre 4 :
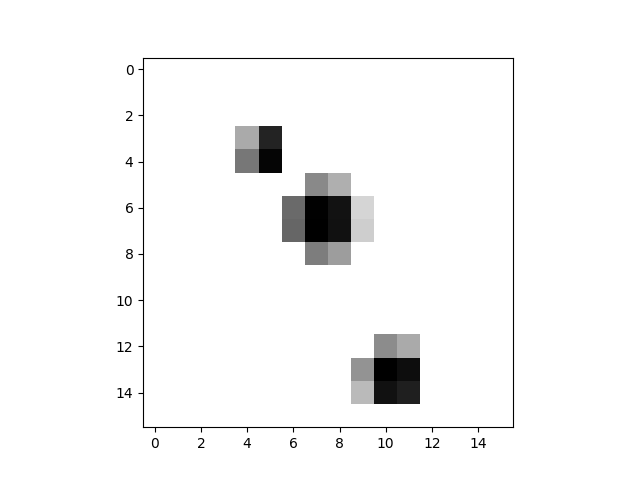
La distribution (pour cette image) a en effet 4 comme mode :
Le problème vient de ce que ⠌ et ⠡ sont des images différentes (les pixels noirs ne sont pas du tout au même endroit) alors qu’elles représentent le même nombre 2. Il faudrait entraîner un réseau de neurones sur des images qui se ressemblent à translation et rotation près. C’est le cas pour la transformée de Fourier bidimensionnelle. En lançant le réseau de neurones convolutif sur des transformées de Fourier de constellations, on obtient plus de succès, avec une précision de 0,6243333220481873. Le réseau de neurones ne se trompe qu’une fois sur trois, et pas de beaucoup, puisqu’au lieu de
[3, 3, 4, 8, 2, 7, 4, 5, 3, 4]il trouve
[3, 4, 5, 9, 3, 6, 4, 6, 3, 4]donc (ici) 6 erreurs sur 10 mais des erreurs d’une seule valeur à chaque fois (par exemple 4 au lieu de 3). Dans ce cas (deuxième valeur), la distribution est presque précise :
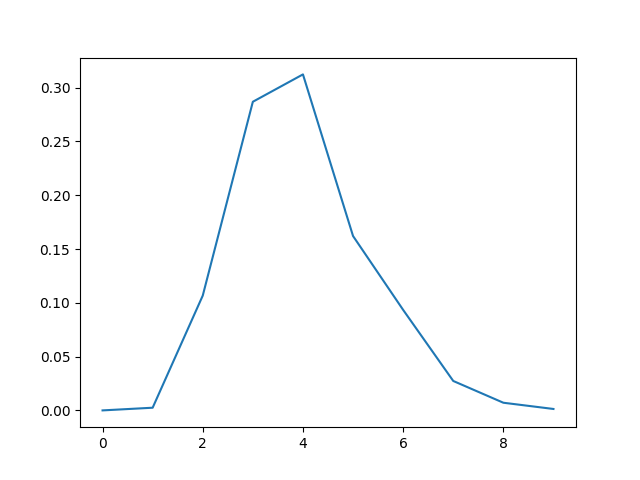
Le mode 4 (erroné) dépasse de peu la valeur correcte 3.
Et si on comptait quand même ?
L’algorithme par transformée de Hough ne fait que repérer les graines (des cercles) et les compter. Mais cela peut être utile à un joueur de m’raha wa n’tso parce que, comme lui, la machine compte les graines sans les toucher. Seulement il faut d’abord qu’elle reconnaisse les graines, indépendamment de leur orientation, ce qui va passer par l’apprentissage : la machine doit apprendre à reconnaître une graine. L’affichage de la caméra intelligente après apprentissage pourrait ressembler à ceci :

Cela mènerait à un autre type de TP, portant sur une caméra intelligente (smart cam) où les élèves n’auraient qu’à apprendre à la machine à reconnaître un nouvel objet (une graine) et après cette phase d’apprentissage supervisé, on testerait la machine sur des constellations : la machine compte correctement si elle reconnaît précisément les graines, et
- sous-compte si elle ne reconnaît pas certaines graines (elle ne les voit pas bien),
- sur-compte en cas de faux positifs (une tache d’ombre prise pour une graine par exemple).
Laisser un commentaire